Environment Variables: Config Outside Your Code
Think of a .env file as a Post-it note of secrets for your app, kept separate from your codebase. Use it for API keys or database URLs that change between environments. The biggest mistake is committing your .env file to Git, exposing all your secrets.

package.json: The Blueprint for Your Node.js Project
The package.json file is the blueprint for a Node.js project, listing its dependencies and runnable scripts. It's essential for installing libraries (`npm install`) and running tasks (`npm test`).

Libuv: The Engine Behind Node.js Async I/O
Libuv is the C library that powers Node.js's non-blocking I/O. It translates JavaScript's event loop into high-performance async calls for the host OS. The footgun is thinking this makes Node multi-threaded; it uses an event loop and a thread pool.

Go's Worker Pool Pattern: Capping Concurrency
A worker pool caps concurrency by using a fixed number of goroutines to process jobs from a queue. Use it for rate-limiting API calls or processing files without spawning unlimited goroutines.

Go Cobra: Build Complex CLIs Like `kubectl`
Cobra gives your Go CLI a command tree, like `git remote add`. It's for apps with nested commands and persistent flags, not just simple tools. The footgun is using it for a single command when Go's `flag` package would suffice.

Buffered I/O: Batch System Calls for Speed
Buffered I/O batches many small reads or writes into fewer, larger system calls, trading a small amount of memory for a huge speed boost. It's essential for tasks like writing log files line-by-line, preventing a system call for every single line.

Go vs. Rust: Why String Indexing Is Tricky
Rust prevents direct string indexing to force correctness, while Go treats strings as raw byte slices. This matters for non-ASCII text where characters span multiple bytes. The footgun: Go's `s[i]` can corrupt data; Rust's `&s[..i]` can panic.

Phantom Reads: When New Rows Appear Mid-Transaction
A phantom read occurs when a transaction repeats a query and finds new rows that match its search criteria, inserted by another committed transaction. It's common in reporting jobs that need a stable set of data.

Multi-Region Databases: Resilience, Latency, and Compliance
A multi-region database is a strategy for resilience, low latency, and data compliance. It's used to survive region outages, keep data in-country, and serve reads close to users. The footgun is managing low-level replica placement directly, which is complex.

Hash-Based Aggregation: Grouping Data Without Sorting
Hash-based aggregation uses a hash table to group data for functions like COUNT or SUM, avoiding a costly sort. It's used in database query engines for GROUP BY operations, especially when distinct groups fit in memory.

Multi-Leader Replication: Enabling Writes Across Datacenters
Multi-leader replication allows multiple nodes to accept writes, avoiding a single-leader bottleneck. It's used in multi-datacenter systems for low-latency local writes and in offline apps. The main footgun is resolving write conflicts from concurrent updates.
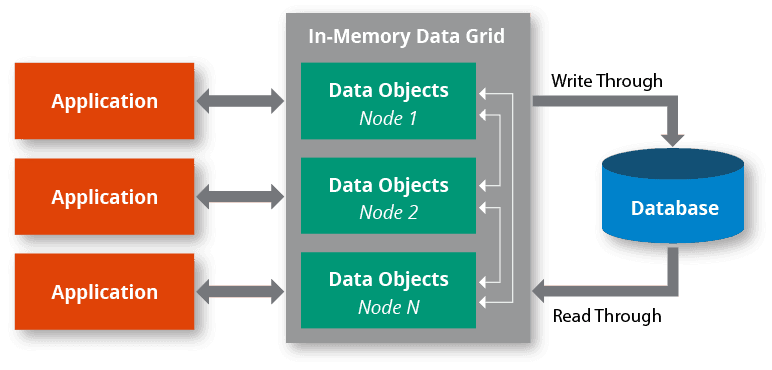
In-Memory Data Grid: A Shared RAM Pool for Your Cluster
An In-Memory Data Grid (IMDG) pools the RAM of multiple computers into one massive, shared data space. It's for high-speed processing on datasets too large for one machine. The footgun is mistaking it for a simple cache; it also provides parallel computation.

Continuous Queries: Automating Time-Series Aggregation
A continuous query automatically aggregates real-time data on a schedule. Use it to create downsampled rollups, like hourly averages from raw sensor data, storing results in a new series.
Faceted Search: Guided Drill-Down for Large Datasets
Faceted search turns a massive result list into an interactive drill-down experience, like the filters on a shopping site. It's used in e-commerce and document libraries where items have structured attributes.

Cache-Aside Pattern: Your App Owns the Cache
The Cache-Aside pattern makes your application the gatekeeper for the cache. On a read, your code checks the cache first; on a miss, it fetches from the database and writes to the cache. This speeds up read-heavy apps. The key footgun is stale data.

Delta Lake: Database Reliability for Your Data Lake
Delta Lake adds a transaction log to your data lake, giving you database-like reliability over raw files. This enables ACID transactions, schema enforcement, and unified batch/streaming pipelines.
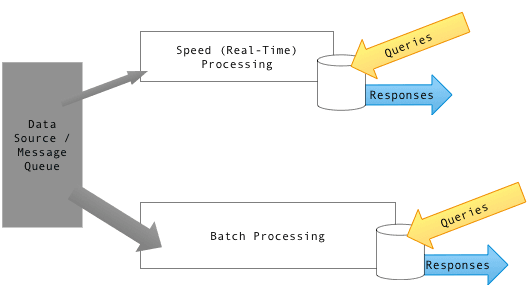
Lambda Architecture: Batch + Stream for Big Data
Lambda Architecture handles massive datasets by combining slow, accurate batch processing with fast, real-time stream processing. It's used for analytics needing both historical and live views.

Data Pipelines: From Raw Data to Actionable Insights
A data pipeline is the plumbing for your data, moving it from raw sources to a refined state for analysis. It feeds dashboards and ML models by cleaning data from APIs and databases. The key footgun is choosing batch processing for real-time needs.
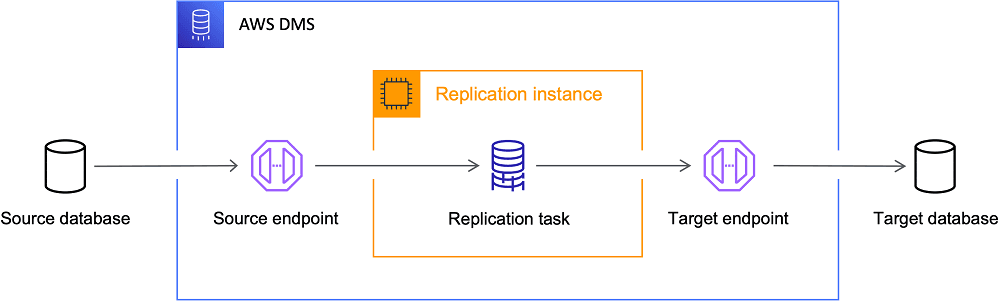
AWS DMS: Your Managed Database Migration Engine
AWS DMS is a managed service for migrating databases. It acts like a replication server you point at a source and target, handling the data transfer. It's used for one-time migrations to AWS or for continuous replication.

Compute & Storage Separation: Scale One Without the Other
This architecture treats your data warehouse (cheap storage) and query engine (expensive compute) as separate services. You can scale compute for peak demand without overprovisioning storage.