
Walk me through Canny edge detection and why it beats Sobel thresholding
Tests multi-scale edge detection and noise robustness versus raw gradient thresholding. Strong answer lists Gaussian blur, Sobel gradients, non-maximum suppression, double thresholding, hysteresis. Red flag: calling it blurred Sobel without hysteresis or NMS.

How does filter separability optimize Gaussian blur and its complexity?
This tests if you know a 2D Gaussian separates into two 1D convolutions. A strong answer gives complexity as O(N^2 K^2) dropping to O(N^2 K) for an N-by-N image and K-by-K kernel. A red flag is claiming all kernels are separable or omitting dimensions.

Zero-padding vs reflect vs replicate padding and their visual artifacts
This tests boundary assumptions in convolution. Zero-padding adds black borders causing dark vignettes; reflect padding mirrors edges for continuity; replicate padding repeats edge values outward. A red flag is saying padding choice does not affect outputs.

How does the Sobel operator approximate image gradients for edge detection?
This tests discrete gradient approximation via separable convolution. A strong answer covers 3x3 Gx and Gy kernels as smoothed central differences, then combines magnitude as sqrt(Gx^2 + Gy^2) or L1 norm. A red flag is treating them as arbitrary blur filters.

How would you implement a simple box blur on a grayscale image?
WHAT IT TESTS: Spatial convolution and image filtering basics. ANSWER OUTLINE: Iterate interior pixels, sum the N by N neighborhood, divide by kernel area, write to a new buffer. RED FLAG: In place updates that blur already blurred values.

Describe the BRDF, its advantage over Lambertian, and critical CV tasks
Tests 4D view-dependent reflectance. Strong answers define BRDF as dL_r/dE_i (sr^-1) over four angles; note Lambertian is isotropic; cite photometric stereo and shape-from-shading where specularity breaks the model. Red flag: calling it albedo.
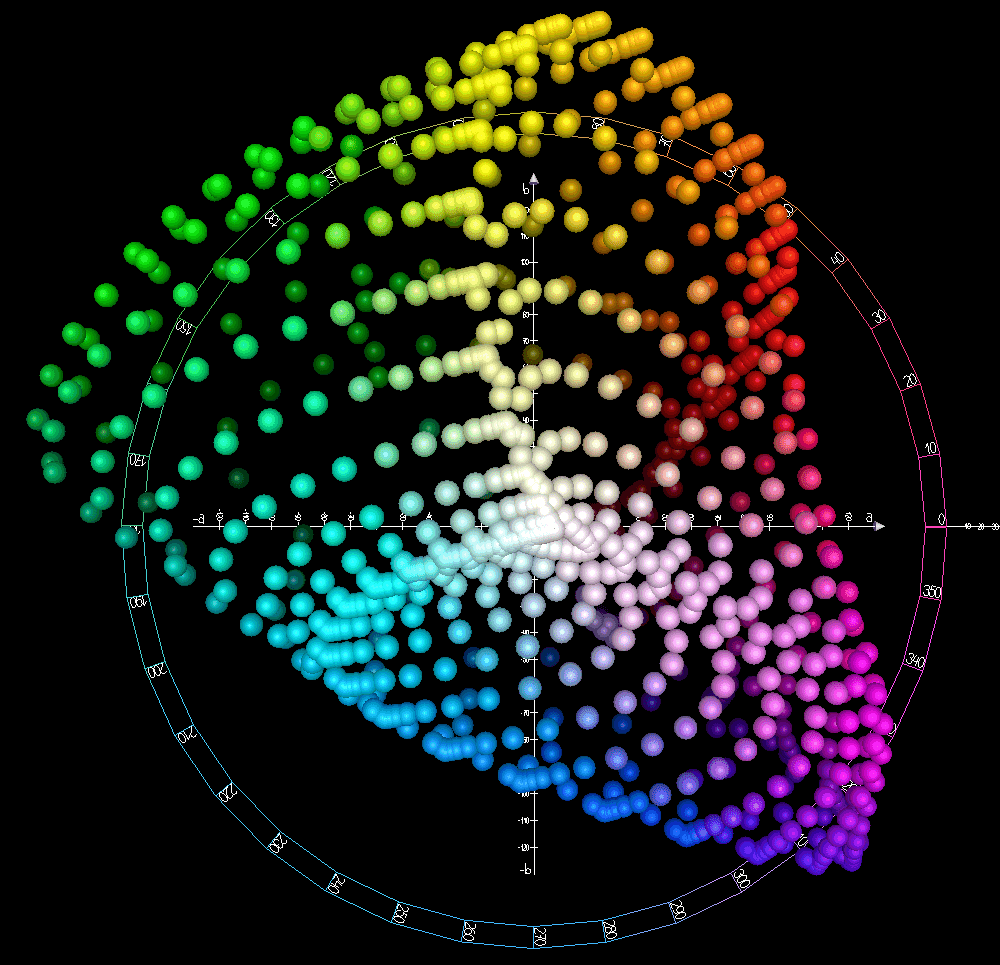
Why is RGB Euclidean distance a poor measure of perceptual color difference?
This tests perceptual uniformity. A good answer explains that RGB distance does not match human vision, then describes CIELAB as a space where deltas approximate perceived differences, making segmentation align with human vision.

Compare YCbCr and RGB. Why chroma subsampling for compression?
Tests color decorrelation and perceptual redundancy. Contrast correlated RGB with YCbCr's luma-chroma split; eyes resolve brightness better than color, so 4:2:0/4:2:2 cuts chroma bandwidth ~50-75% with little loss.

Explain the pinhole camera model and intrinsic matrix K
Tests projective geometry and mapping sensor properties to K. Good answers derive perspective projection via similar triangles, list fx, fy, cx, cy, skew, and explain pixel scaling. Red flag: mixing intrinsics with extrinsics or saying K includes distortion.

Describe a grayscale histogram and its use in exposure and equalization
Tests pixel distribution intuition. A strong answer covers intensity bin counts, left or right clustering for exposure errors, and CDF-based redistribution for equalization. Red flag: calling equalization min-max stretching without cumulative mapping.

What is the difference between lossy and lossless image compression?
This tests irreversible discard versus perfect reconstruction. A strong answer defines lossy as dropping detail, lossless as fully reversible, names JPEG, PNG, and chooses lossless for masters, lossy for web. Red flag: claiming lossless is always smaller.

Non-Maximum Suppression: One Box Per Object
Non-Maximum Suppression (NMS) ensures each detected object gets just one bounding box. It sorts all proposed boxes by confidence, keeps the best one, and discards others that overlap it too much.

3D Object Detection: Seeing in Depth, Not Just Pixels
3D object detection adds depth to a 2D flat view, understanding an object's true size, distance, and orientation. It's vital for autonomous cars and robotics that need spatial awareness.
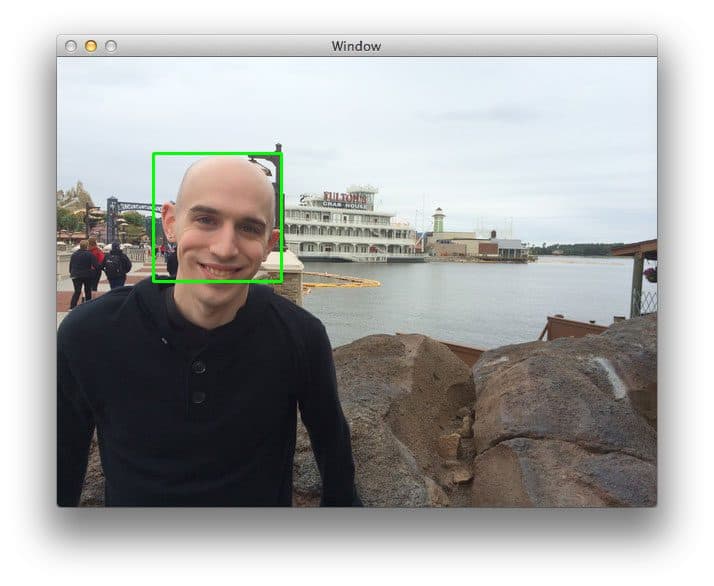
Sliding Windows: Scanning Images for Objects
A sliding window scans an image with a fixed-size box to find objects. At each location, a classifier checks the window's contents. Combined with an image pyramid, it can detect objects at various scales, localizing exactly where they are.

BRIEF: Fast, Compact Binary Feature Descriptors
BRIEF describes image features as a compact binary string instead of a complex vector. This makes it extremely fast for real-time matching on low-power devices. The footgun: its raw form isn't rotation-invariant, trading that robustness for raw speed.

TensorRT: From Trained Model to Production Speed
TensorRT is a compiler that turns a trained model into a specialized, high-speed engine for a specific NVIDIA GPU. It's used to deploy models in production where low latency is critical.

Model Quantization: Trading Precision for Performance
Model quantization trades numerical precision for a smaller memory footprint. It reduces model weights from high-precision types like fp32 to lower ones like int8 or int4, making large models fit on consumer hardware.

Coded Aperture: Imaging Without a Lens
A coded aperture images radiation that can't be focused, like X-rays. Instead of a lens, it uses a patterned mask to cast a complex shadow, which is then mathematically decoded into an image. It's crucial for X-ray astronomy.

Tone Mapping: Fitting HDR Light onto LDR Screens
Tone mapping compresses a vast range of light (HDR) to fit on a standard screen (LDR). It's how HDR photos and games look good on your monitor instead of having blown-out whites or crushed blacks. The footgun is creating unnatural, "over-cooked" images.

Visual Commonsense Reasoning (VCR): From Recognition to Cognition
VCR pushes AI from simple object recognition to human-like reasoning by asking not just 'what' is in an image, but 'why.' Models must select both the correct answer and the correct rationale, exposing models that guess answers based on shallow correlations.