
Model Drift: When Good Models Go Bad
A model is a snapshot of the world; model drift is the alarm that fires when the world changes but your snapshot has not. It detects when production data no longer statistically matches the training data, a common issue for models predicting user behavior.
Distributed Model Training: Splitting the Workload
Don't wait for one GPU to finish; use many. Distributed training splits a model's workload across multiple processors to finish faster. It's essential for massive deep learning models.
ML Inference Endpoint: The API for Your Model
An ML inference endpoint is the stable API URL your application calls to get predictions. It separates the public URL from the underlying model, letting you swap models without changing client code.
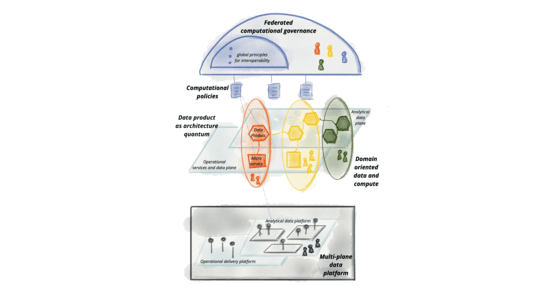
Data Mesh: From Central Data Lake to Distributed Ownership
Data Mesh decentralizes data ownership, moving it from a central team to the business domains that create it. This approach, like microservices for data, is for orgs where a monolithic data lake has become a bottleneck.
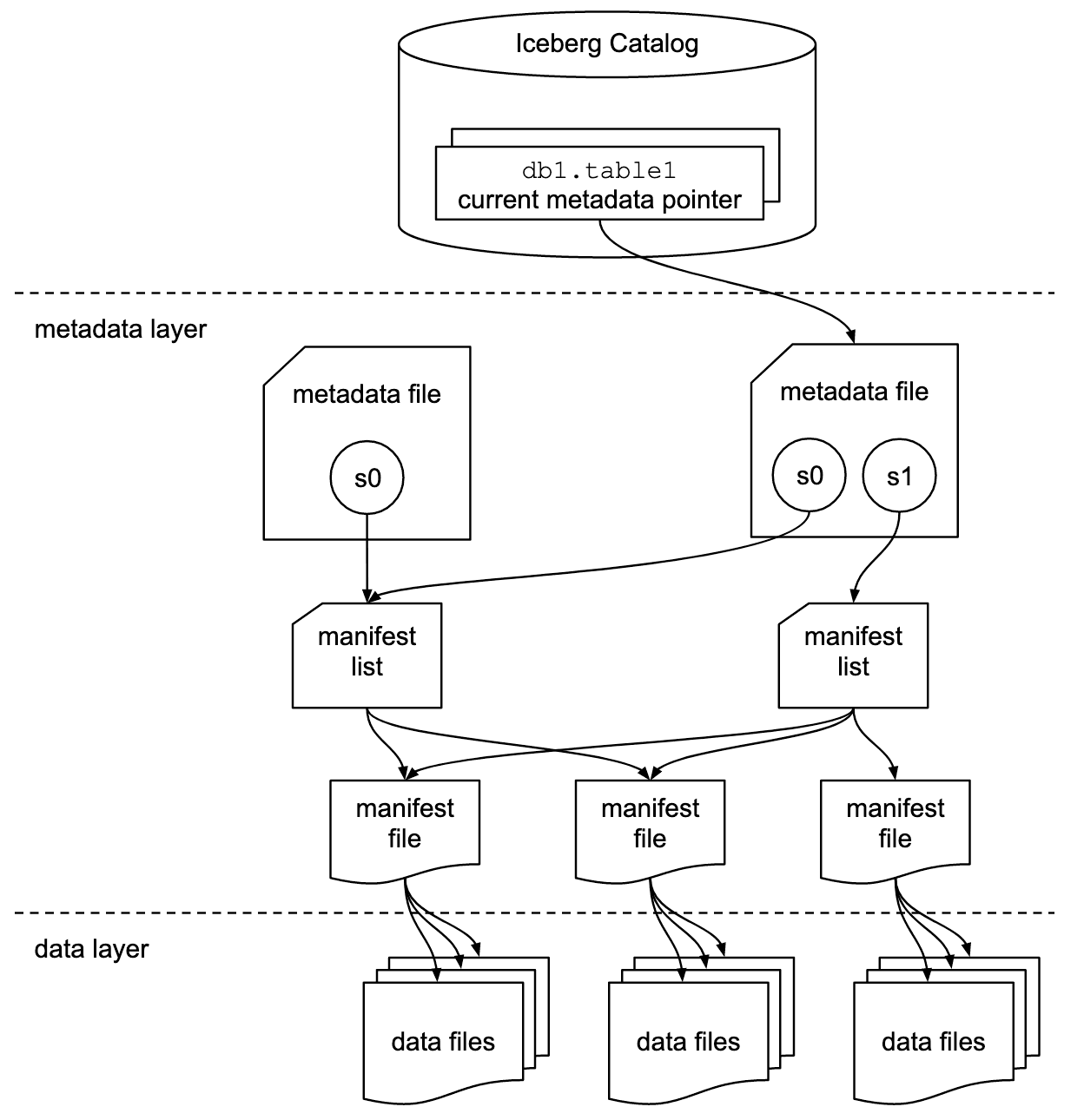
Apache Iceberg: A Table Format for Huge Datasets
Apache Iceberg is an open table format for huge analytic datasets. It adds a metadata layer to files in object storage, enabling engines like Spark and Trino to work with transactional guarantees. The footgun: it's a format, not a query engine itself.
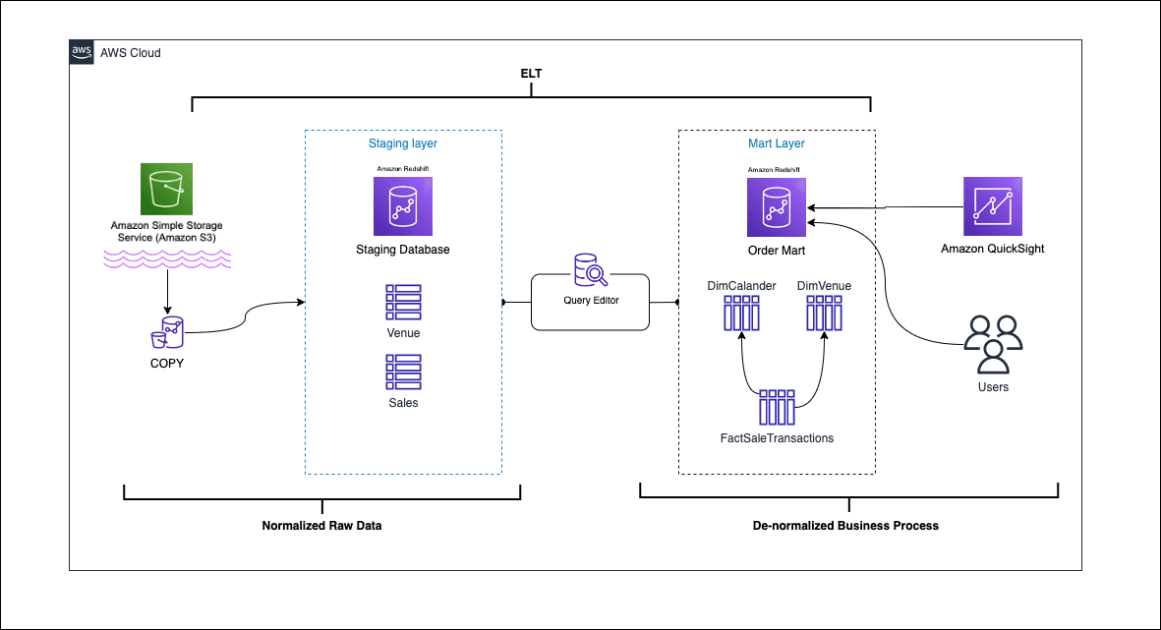
Dimensional Modeling: Facts vs. Dimensions
Dimensional modeling organizes data like a story: 'facts' are what happened (sales numbers) and 'dimensions' are the who, what, and where (customer, product). It's the foundation for data warehouses, turning raw data into analyzable BI reports.

Batch vs. Stream Processing: When to Process Data
Batch processing is like a nightly report, crunching a full day's data at once. Stream processing is a live feed, handling events as they arrive. Use batch for ETL jobs and stream for real-time fraud detection.

Cloud Unit Economics: Tying Spend to Value
Instead of just a total cloud bill, unit economics calculates cost per meaningful unit, like 'cost per customer.' This helps justify rising costs with business growth and lets product owners make data-driven pricing tradeoffs.

Showback vs. Chargeback: Who Pays the Cloud Bill?
Showback shows teams their cloud costs for visibility; Chargeback makes them pay for it by moving costs to their budget. This helps control cloud spend by making engineers cost-aware. The footgun is treating Chargeback as inherently more mature than Showback.

FinOps Framework: Aligning Cloud Cost with Business Value
FinOps treats cloud spend as a business metric, not just an IT cost. It provides a shared framework for engineering, finance, and business to collaborate on data-driven spending decisions.

Cloud Rightsizing: Stop Overpaying for VMs
Rightsizing stops you from overpaying for idle cloud capacity. It involves analyzing CPU and memory usage to shrink over-provisioned VMs. Always collaborate with application owners before making changes.

Cloud Budgets: Your Guardrail Against Overspending
A cloud budget is a spending alarm for your cloud account. It warns you when costs approach a limit you've set, preventing surprise bills. Use it to track monthly spend or monitor usage. The main footgun: billing data lags, so you can overspend before an.
AWS Cost Explorer: Visualize and Forecast Your Cloud Spend
Cost Explorer is your cloud bill's interactive dashboard, turning raw data into trend graphs and forecasts. Use it to find which service is driving up costs or to predict next quarter's bill. The main footgun: once enabled, it cannot be disabled.
Consolidated Billing: Combine Cloud Bills for Bigger Discounts
Consolidated Billing is like a family phone plan for AWS accounts. It rolls multiple accounts into one bill, letting you share volume and savings plan discounts across the entire organization.
IaC State: The Map Between Your Code and the Cloud
IaC state is the source of truth mapping your code to real-world resources, acting as your tool's memory. Terraform uses a state file to plan updates, while other tools use a service backend. The footgun: never commit state files to Git; they lack locking and.
The Saga Pattern: Transactions Across Microservices
The Saga pattern manages transactions across services by chaining local operations. If a step fails, compensating actions undo previous work. It's common in booking systems.

Serverless State Machines: The Conductor for Your Functions
A serverless state machine is the conductor for your microservices, telling each function when to run and how to handle errors. It's built for multi-step processes like ETL pipelines or coordinating parallel tasks. The footgun is creating a visual monolith.
Idempotent Event Handlers: Don't Double-Count Events
An idempotent event handler ensures processing the same event multiple times has the same effect as processing it once. This is vital in event-driven systems to prevent data corruption from redelivered messages. The footgun is assuming exactly-once delivery.
AWS SAM: A Shorthand for Serverless on AWS
Think of AWS SAM as a developer-friendly shorthand for defining serverless applications. It simplifies creating Lambda functions and APIs by abstracting away verbose CloudFormation syntax, letting you build and test locally before deploying.

Cloud Native Buildpacks: No More Dockerfiles
Cloud Native Buildpacks turn source code into container images without a Dockerfile. This lets platform teams enforce security and best practices, while app developers just push code. The footgun is assuming they're simple; they're a full build system.