
How does text guide Stable Diffusion via U-Net cross-attention?
Tests whether you know text embeddings condition the U-Net through cross-attention. Good answers explain that image features query text keys and values at every layer. Red flag: claiming the prompt is concatenated to the image latent.

Key latent space difference between Autoencoder and VAE, and generative use
This tests deterministic versus probabilistic latent representations. Standard autoencoders encode fixed points; VAEs encode distributions. Sampling the regularized latent distribution generates new data. Red flag: calling VAEs mere noise adders.
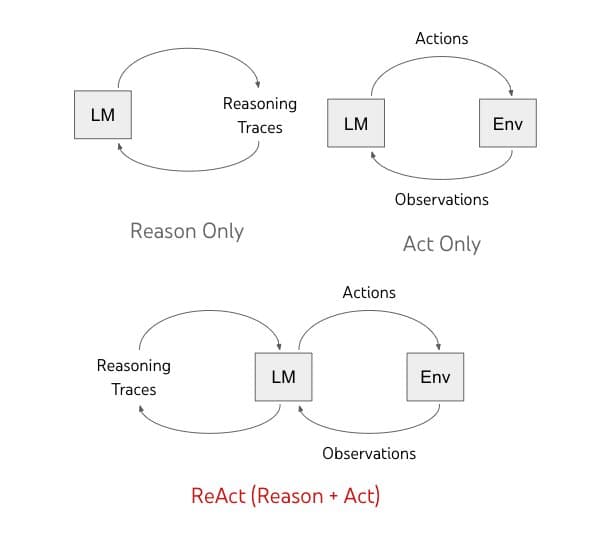
Describe a ReAct agent architecture for multi-step dependent tool calls
WHAT IT TESTS: Designing loops that interleave reasoning and tool use across steps. ANSWER OUTLINE: Sketch ReAct's thought-action-observation cycle; keep state in an append-only trajectory; re-plan after each observation.

Walk me through building a weather agent with get_weather
WHAT IT TESTS: The LLM tool-use loop separating inference from execution. ANSWER OUTLINE: Register get_weather, let the model emit parameters, execute it yourself, feed the result back, then synthesize the answer. RED FLAG: Claiming the LLM calls the API.
How does function calling work in modern LLMs?
WHAT IT TESTS: whether you see function calling as client-side structured generation, not model execution. ANSWER OUTLINE: schemas in the prompt; model emits JSON name and arguments; client executes and returns results.

How would you architect a multi-turn conversational RAG system?
This tests memory and query reformulation design beyond single-turn RAG. A strong answer covers 5-10 turn windows, LLM-based rewriting with coreference resolution, hybrid fallbacks, and summarized memory.
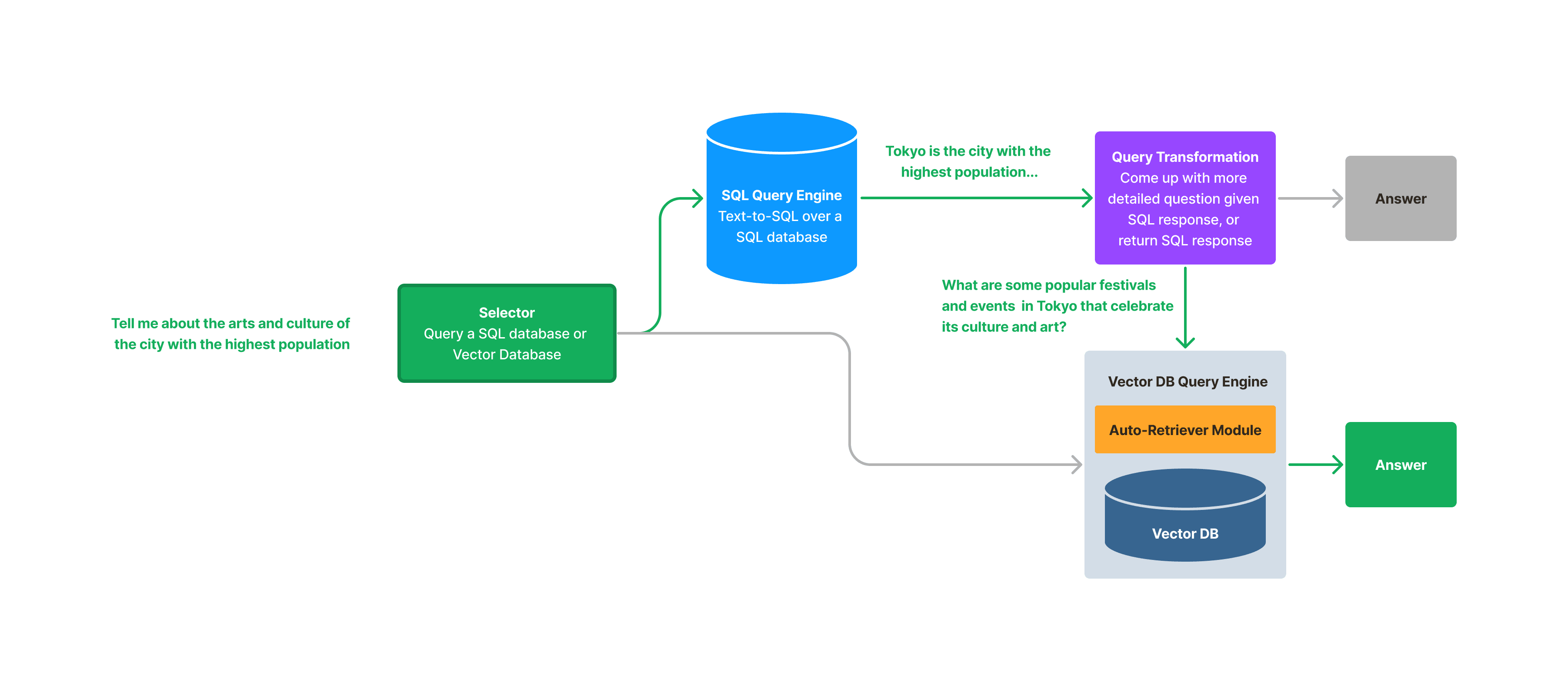
How would you modify retrieval architecture for hybrid text and SQL RAG?
It tests unified retrieval across unstructured text and structured SQL. Outline a query planner that routes to vector search or text-to-SQL, joins the results, and synthesizes a final answer. Never suggest embedding the whole database as text chunks.

Why does your RAG ignore or contradict retrieved context?
Tests separation of retrieval failures from generation grounding in RAG. Strong answers trace symptoms to root causes like bad chunks, prompt ordering, or parametric knowledge override, then outline systematic debugging. Do not just say hallucination.

What does the KL-divergence penalty do in RLHF PPO, and if zeroed?
It tests RLHF reward hacking awareness. The KL penalty anchors PPO to the reference model to stop mode collapse; zeroing it causes over-optimization against the proxy reward model, yielding incoherent outputs.

Walk through RLHF's three stages, outputs, and purposes.
Tests your grasp of the RLHF pipeline end-to-end. A strong answer lists: pretrain an instruction-following LM, train a reward model outputting a scalar preference score, then fine-tune the LM via RL.

Full fine-tuning or LoRA on a tight compute budget?
This tests budget-constrained adaptation for many tasks. A strong answer picks LoRA: it trains only a small number of extra parameters, cutting compute and storage versus full fine-tuning while matching performance.

Describe supervised fine-tuning for a pre-trained language model
Tests if you know SFT aligns a base model to instructions using curated prompt-completion data. A strong answer covers next-token prediction on completions, conversational formats, and small learning rates.
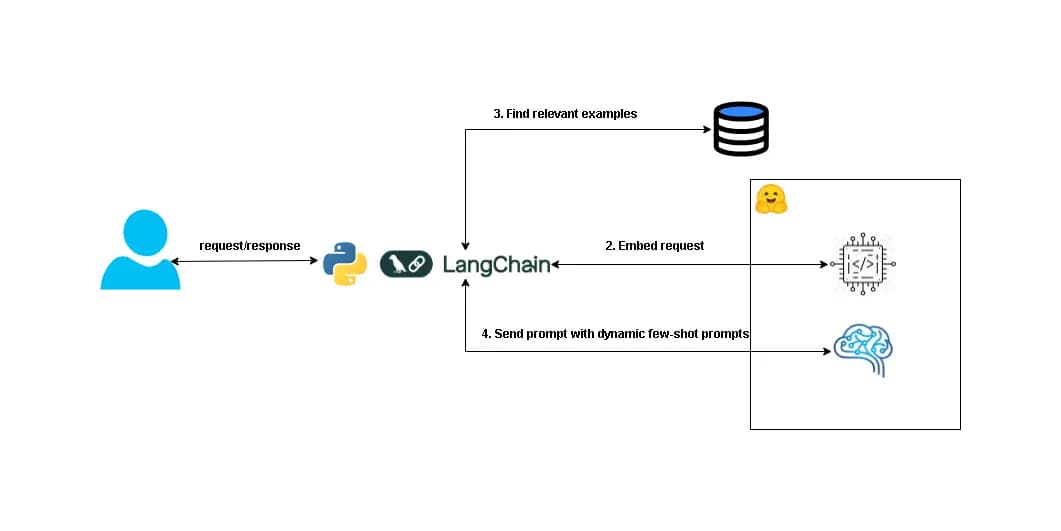
Design dynamic few-shot example retrieval from a vector database
Tests RAG-style prompt engineering with semantic retrieval and latency. Use shared embeddings, approximate nearest neighbors with metadata filters, diversity reranking, and token-bounded prompt templates.

Describe two prompt-based techniques to ensure valid LLM JSON output
This tests output constriction via prompt design. First, embed an exact JSON skeleton with empty values. Second, provide few-shot exemplars mapping inputs to valid JSON. A red flag is suggesting only post-hoc regex repair or larger models.

What causes sudden loss spikes in long pre-training runs?
WHAT IT TESTS: Diagnosing LLM training instabilities under pressure. ANSWER OUTLINE: Name gradient explosions, LR mismatch, FP16 overflow, and poison batches; propose norm checks, rollback, and LR cuts.

Explain data, tensor, and pipeline parallelism and hybrid training strategy
Tests communication and memory tradeoffs of core distributed training strategies. Strong answers contrast data parallelism (shard batch), tensor parallelism (shard layers, all-reduce), and pipeline parallelism (shard stages, p2p), then propose a 3D hybrid…

Why is self-attention O(n^2) and what are the implications?
Tests the attention matrix bottleneck. Strong answers note QK^T yields an N×N matrix, creating quadratic compute and memory that blocks long documents and high-res images. Red flag: confusing model size with activation memory.

Validation loss increases while training loss decreases: what is this?
This tests recognition of overfitting and regularization. A strong answer names it, offers early stopping, dropout or weight decay, and data augmentation or more data. A red flag is suggesting longer training or more parameters without fixing generalization.

Explain word embeddings and why they beat one-hot encoding for large vocabularies
WHAT IT TESTS: dense semantic vectors versus sparse symbolic encodings. ANSWER OUTLINE: embeddings cluster similar meanings in low-dimensional space, while one-hot vectors are orthogonal, huge, and semantically blank.

Google TPU: Built for Matrix Math
A TPU is a specialist ASIC, not a faster GPU; it trades graphics flexibility for matrix-math throughput per watt. Google deploys them for TensorFlow, JAX, and PyTorch at scale. They excel at CNNs but can lag on tasks needing rasterization or recurrent logic.