Describe the architecture of a generic A/B testing framework
WHAT IT TESTS: system design with statistical safety. ANSWER OUTLINE: hash-based user bucketing, config service, pre-registered metrics, and confidence intervals on dashboards. RED FLAG: request-level randomization or skipping power analysis.

Which classical baseline model handles weekly seasonality and upward trend?
Tests matching model structure to data characteristics. Name Holt-Winters triple exponential smoothing; map its level, trend, and seasonal equations to weekly period. Red flag: jumping to SARIMA without explaining why ETS is the natural baseline.
How do you measure forecast accuracy and compare MAE to RMSE?
This tests out-of-sample validation and how MAE and RMSE weight errors. A strong answer demands a train-test split, defines both, and notes RMSE punishes outliers more while MAE is more robust. A red flag is citing in-sample fit instead of held-out error.
Trade-offs between pre-aggregated and raw event data for dashboards
WHAT IT TESTS: Balancing latency, cost, and freshness in analytics. ANSWER OUTLINE: Pre-aggregations trade freshness for speed; raw queries preserve flexibility but spike cost and latency under load.

Propose a North Star Metric for a product you know
WHAT IT TESTS: Can you isolate the one metric capturing user value that predicts business health. A GOOD ANSWER COVERS: definition; your product's metric; how value drives retention and revenue.

Claude Agent for Jira Automates Ticket-to-PR Pipeline
Claude Agent for Jira assigns tickets to Anthropic's agent, which reads criteria and returns draft PRs from a sandbox. This closes the plan-to-code gap that has capped AI gains at 10-15%. Delegate routine bugs and refactors straight from your backlog.
Jira makes AI agents assignable teammates
Jira now lists AI agents as teammates, closing the orchestration gap that wastes the 10-15% productivity lift from AI tools. Agents pick up tickets, update fields, and transition issues with audit trails. Pilot this if your backlog has repetitive triage.

Design a system architecture optimized for rapid product discovery and iteration
Tests architecting for uncertainty via evolutionary principles. Answer: modular granularity, continuous delivery, and automated fitness functions guarding security and data. Red flag: rigid upfront design ignoring orthogonal dimensions or cross-cutting harm.
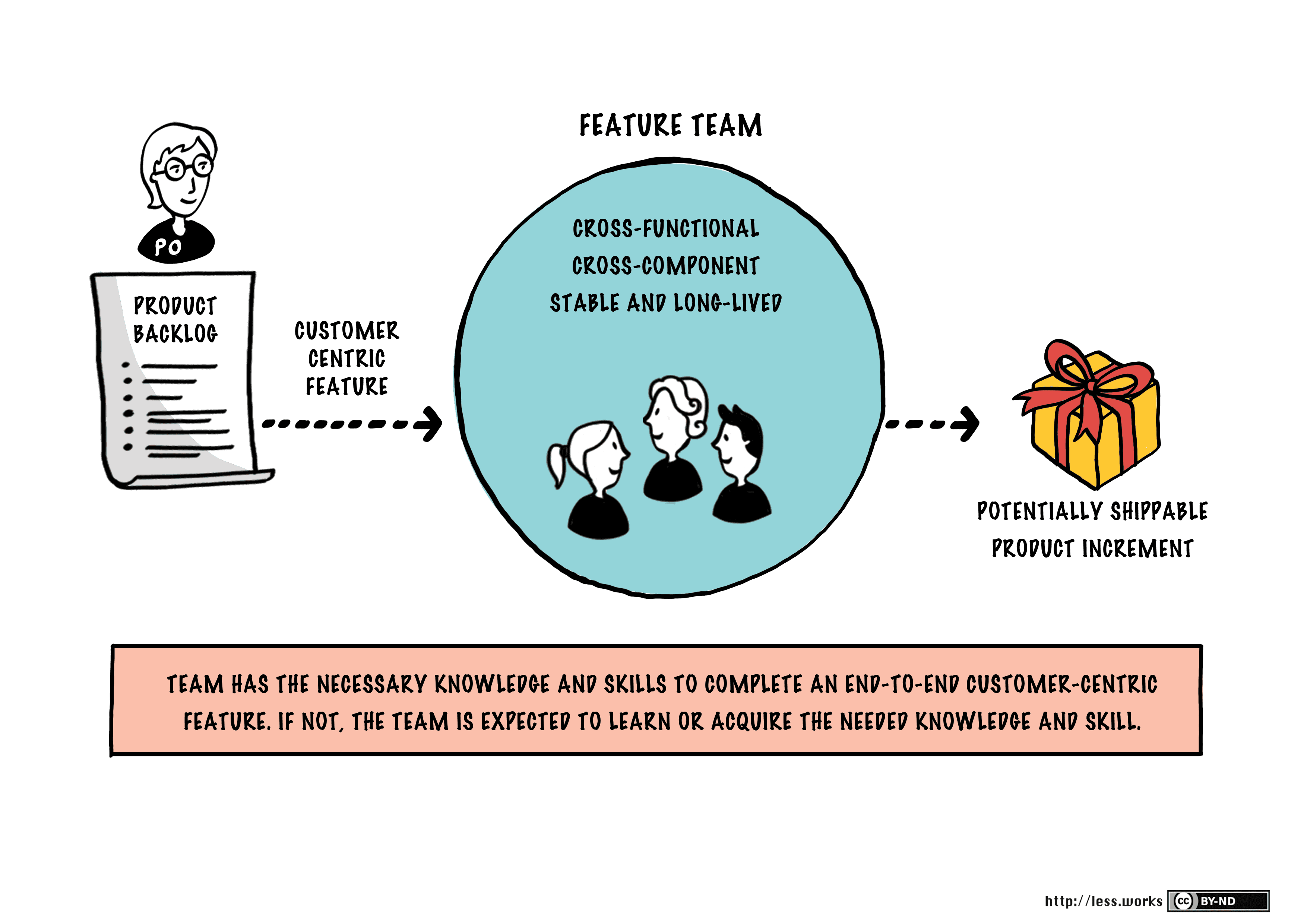
What codebase and CI/CD prerequisites enable LeSS feature teams?
Tests technical enablers for LeSS feature teams. Strong answers cover sub-10-minute CI, trunk-based development, comprehensive test automation, and decoupled architecture. Red flag: claiming coordination replaces shared ownership and continuous integration.

Sprint velocity is highly variable. What technical root causes do you check?
TESTS: Debugging velocity variance with data, not assumptions. OUTLINE: Check scope stability via carryover, flow via cycle time, quality via rework, and estimation via point variance. RED FLAG: Blaming people or treating velocity as a performance target.

How does a self-managing team resolve strong technical disagreements without escalation?
This tests if you see conflict as healthy creative tension. A strong answer covers timeboxed dialogue, multi-voting with reasoning, and the senior dev as neutral facilitator. A red flag is letting the senior dev dictate the answer or escalate to management.

How do you identify and elevate your team's primary constraint using TOC?
WHAT IT TESTS: Systems thinking and metric-driven TOC bottleneck identification. ANSWER OUTLINE: Map value stream, measure queue and cycle times to find the slowest stage, exploit it, subordinate upstream WIP, elevate via automation, repeat.

Explain the difference between Objectives and Key Results in OKRs
WHAT IT TESTS: Separating qualitative vision from quantitative measurement in engineering goals. ANSWER OUTLINE: Objectives inspire direction; Key Results are measurable proof; cite an engineering example on technical quality like uptime.

How would you technically evaluate a major product pivot?
WHAT IT TESTS: Structured feasibility under uncertainty. Strong answers: define requirements and SLOs, timebox spikes to de-risk unknowns, audit architecture, data, infra, security, and team skills against thresholds.

How does product strategy influence architectural decisions? Provide a specific example.
This tests if you tie architecture to product outcomes like iteration speed. A strong answer picks patterns by company stage, cites a concrete tradeoff, and treats reliability as a product feature.
How do you build a 3-year vision supporting roadmap and future options?
This tests strategic planning and executive communication. Map the 1-year roadmap to gaps, invest in extensible primitives, and frame enabling work as optionality with metrics. Red flag: an engineering wishlist disconnected from business outcomes.

Describe a time you influenced the roadmap via a technical opportunity
This tests converting technical insights into business cases that shift roadmaps. A strong answer names the SVPG risk, quantifies value for leadership, identifies who was persuaded, and cites discovery artifacts.

How do you communicate technical complexity and propose alternatives to a PM?
Tests translation of technical complexity into product tradeoffs. Strong answers lead with the business goal, quantify timeline and risk, then offer 2-3 simpler options with clear tradeoffs. Red flag: jargon-heavy pushback or a hard no without alternatives.

Propose a long-term strategy to decompose a monolith while maintaining API stability
This tests strategic prioritization and incremental migration without ecosystem breakage. Start with simple decoupled capability, go macro first then micro, split vertically by domain owning data, and use atomic steps with facades to preserve APIs.

How would you detect, mitigate, and penalize a noisy neighbor?
This tests multi-tenant fairness and governance. A strong answer covers tenant telemetry, graduated throttling, autoscaling with cost caps, and penalty tiers that curb abuse yet allow spikes. Red flag: hard limits before detection or graduated response.