
Explain the difference between Objectives and Key Results in OKRs
WHAT IT TESTS: Separating qualitative vision from quantitative measurement in engineering goals. ANSWER OUTLINE: Objectives inspire direction; Key Results are measurable proof; cite an engineering example on technical quality like uptime.

How would you technically evaluate a major product pivot?
WHAT IT TESTS: Structured feasibility under uncertainty. Strong answers: define requirements and SLOs, timebox spikes to de-risk unknowns, audit architecture, data, infra, security, and team skills against thresholds.

How does product strategy influence architectural decisions? Provide a specific example.
This tests if you tie architecture to product outcomes like iteration speed. A strong answer picks patterns by company stage, cites a concrete tradeoff, and treats reliability as a product feature.
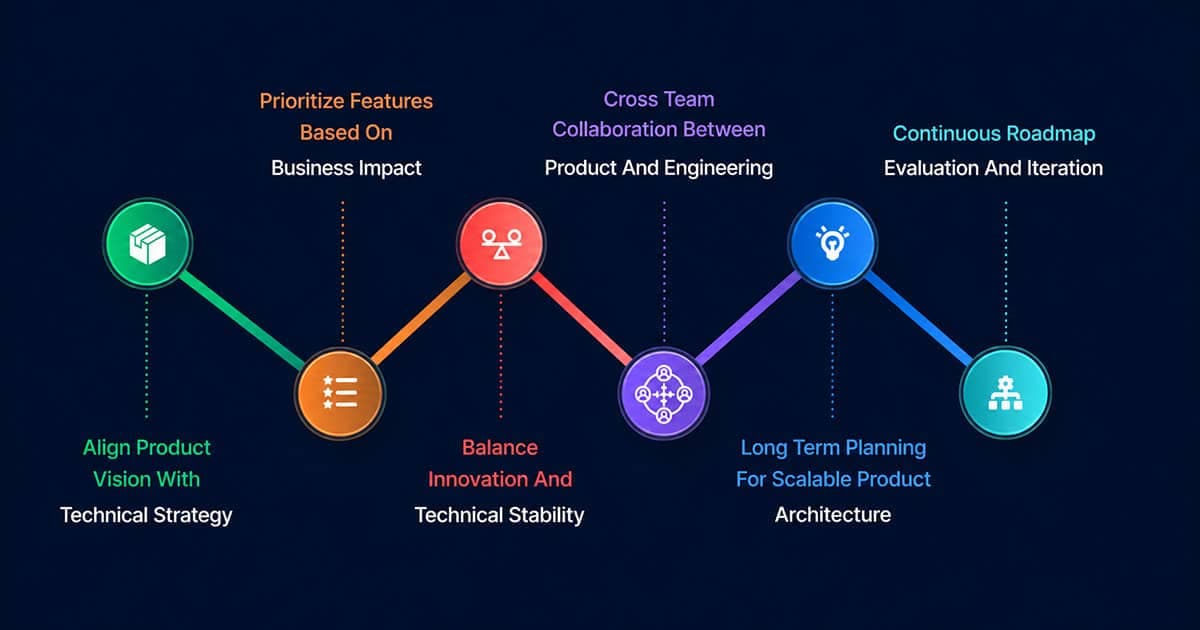
How do you build a 3-year vision supporting roadmap and future options?
This tests strategic planning and executive communication. Map the 1-year roadmap to gaps, invest in extensible primitives, and frame enabling work as optionality with metrics. Red flag: an engineering wishlist disconnected from business outcomes.

Describe a time you influenced the roadmap via a technical opportunity
This tests converting technical insights into business cases that shift roadmaps. A strong answer names the SVPG risk, quantifies value for leadership, identifies who was persuaded, and cites discovery artifacts.

How do you communicate technical complexity and propose alternatives to a PM?
Tests translation of technical complexity into product tradeoffs. Strong answers lead with the business goal, quantify timeline and risk, then offer 2-3 simpler options with clear tradeoffs. Red flag: jargon-heavy pushback or a hard no without alternatives.

Propose a long-term strategy to decompose a monolith while maintaining API stability
This tests strategic prioritization and incremental migration without ecosystem breakage. Start with simple decoupled capability, go macro first then micro, split vertically by domain owning data, and use atomic steps with facades to preserve APIs.

How would you detect, mitigate, and penalize a noisy neighbor?
This tests multi-tenant fairness and governance. A strong answer covers tenant telemetry, graduated throttling, autoscaling with cost caps, and penalty tiers that curb abuse yet allow spikes. Red flag: hard limits before detection or graduated response.

Compare webhooks to sandboxed plugins for monolith extensibility
Tests distributed vs in-process extensibility. Webhooks are async, loosely coupled, and isolated but add network latency. Sandboxed plugins run in-process for low-latency UI depth yet need strict host API permissions and lifecycle gating.

Roll out a breaking change to a core public API
This tests risk management while evolving a public API contract. A strong answer covers versioning, phased deprecation with SLAs, migration tooling, and proactive communication. Red flag: proposing a hard cutover without sunset or migration support.

Describe the chicken-and-egg problem for a two-sided platform and a seeding strategy.
Tests grasp of interdependent platform value and why seeding empty rooms matters. Answer: each side needs the other; propose a one-sided technology core to attract first users and pull the second side.

Design a cross-product user journey data architecture
This tests portfolio-scale data platform design. A strong answer outlines streaming event ingestion, a unified identity graph, consent-aware PII vaults, and schema registries with data contracts.

What technical areas would you investigate in acquisition due diligence?
Tests strategic integration risk beyond code quality. Cover: architecture compatibility and tech debt; data model overlap and migration cost; security and compliance gaps; team retention; roadmap conflicts.

Design a cross-product feature flag strategy for coordinated release
This tests distributed coordination across service boundaries. A strong answer proposes a unified namespace, central config with local caches, and one user-scoped gate evaluated consistently in both products.

Architect a 14-day Pro trial with abuse prevention
Tests stateful billing lifecycle and anti-abuse tradeoffs. Strong answers cover: idempotent trial state machine with scheduled expiry; retention on downgrade; progressive friction via device intel and rate limits; and behavioral monitoring.
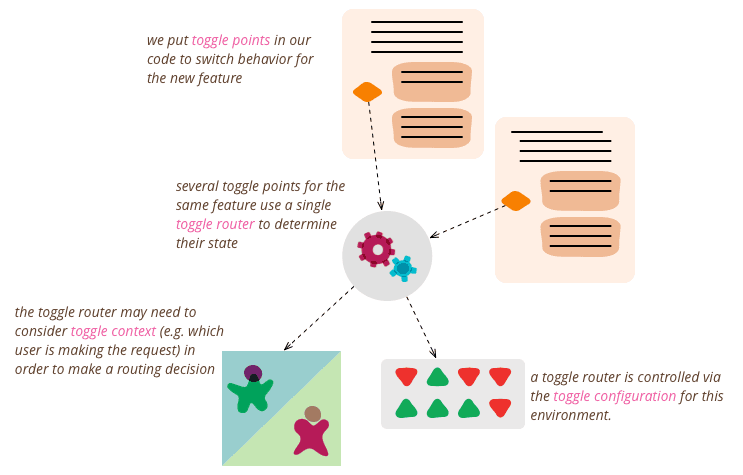
Describe an architecture that decouples business launch from code deployment
This tests feature-flag architecture separating deployment from release. Strong answers cover toggle categories and decision decoupling. They need lifecycle management to limit carrying cost. Red flag: treating flags as permanent or ignoring toggle debt.
.avif&w=3840&q=75)
What pre-launch tools prevent support ticket escalations to engineering?
Tests proactive operational design versus reactive firefighting. Great answers include real-time health dashboards, automated ticket triage with user context, self-service runbooks, and escalation guardrails with pre-populated logs.

How do you technically implement an A/B test for onboarding flows?
Tests experiment pipeline design: deterministic user bucketing, an exposure event before rendering, and an event schema linking actions to variant_id. Red flag: re-randomizing per session or skipping exposure logs.

How does a fixed marketing launch date change your development approach?
WHAT IT TESTS: Whether you treat fixed deadlines as a scope negotiation challenge while guarding quality. ANSWER OUTLINE: Acknowledge the business case, fix time and flex scope via Iron Triangle, front-load risk. RED FLAG: Cutting tests or scope for the date.

How do you justify API refactoring over new features to stakeholders?
Tests turning technical drag into business cost. Frame cruft as interest on velocity; quantify incident cost, MTTR, and lead time; advocate incremental cleanup with product work. Avoid demanding a six-month rewrite without product tie-in.