Design a system for batch scoring millions of customer records daily
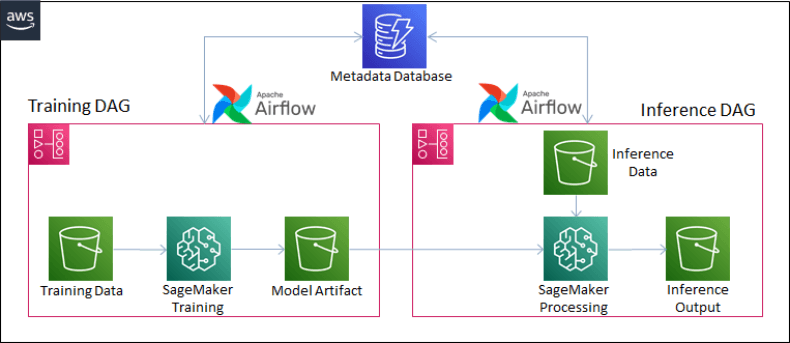
WHAT IT TESTS: Decoupling orchestration, storage, and compute for batch inference with cost/SLA in mind. ANSWER OUTLINE: Shard jobs via scheduler; partition storage; right-size CPU/GPU on spot; retry. RED FLAG: One monolithic VM or real-time APIs for batch.
WHAT IT TESTS: Whether you can architect orchestration, storage, and compute layers for batch inference on millions of rows while balancing throughput, fault tolerance, and cost. ANSWER OUTLINE: Shard jobs with MWAA or Step Functions; store partitioned data in S3; run SageMaker Batch Transform with CPU or GPU instances sized to model complexity; use spot instances and CloudWatch. RED FLAG: Proposing a single long-running server, real-time REST endpoints, or ignoring data partitioning and idempotency.
Read the original → aws.amazon.com
- #mlops
- #batch inference
- #aws
- #sagemaker
- #system design
Get five bites like this every day.
Tezvyn delivers a daily feed of 60-second tech bites with quizzes to lock in what you learn.