
Most LLM Apps Need Workflows Not Agent Frameworks
Most LLM apps ship faster and more reliably as deterministic workflows than autonomous agents. Plain Python with structured outputs and local functions beats CrewAI and LangGraph for debugging. Map control flow in code before importing any agent framework.

ORPilot JSON IR Ends Solver Lock-In
ORPilot's open-source IR captures optimization models as solver-agnostic JSON, letting teams swap solvers or update data without calling the LLM again. It separates model structure from solver syntax, making LLM-generated OR models reproducible in production.

Default Churn Thresholds Waste $86 per Customer
90% of 36 IBM Telco churn analyses use F1 and a 0.5 threshold, assuming equal costs for false positives and negatives. That is wrong by 13x, burning $86 per customer, or $8.6M at 100k subscribers. Swap accuracy for profit curves tied to LTV and CAC.

Low GPU utilization on multi-GPU instance: diagnose and right-size
Tests distributed bottleneck triage. Strong answers profile CPU/GPU/disk, compare gradient sync time to compute, validate per-GPU batch size, and check NVLink vs PCIe. Red flag: suggesting more GPUs before ruling out data starvation or all-reduce overhead.

Compare and contrast Apache Airflow versus Kubeflow Pipelines for ML orchestration
This tests matching orchestrators to ML constraints. A strong answer contrasts Airflow's task scheduling and backfills with Kubeflow's K8s-native GPU scaling, choosing based on team skills.

Explain dynamic batching in inference servers and its trade-off
WHAT IT TESTS: Inference scheduling and the latency-vs-throughput trade-off. ANSWER OUTLINE: Dynamic batching launches when a time window or max size is met, improving throughput over static batching, but short ones wait for the slowest.
Design a multi-tenant GPU serving system for hundreds of fine-tuned models
Tests GPU memory tradeoffs versus cold-start latency in multi-tenant serving. Strong answers propose tiered CPU staging, predictive pre-warming, and disaggregated prefill and decode. Red flag: keeping all models GPU-resident or ignoring transfer overhead.

Compare Canary and Blue/Green ML deployments and model-specific metrics
WHAT IT TESTS: Model quality vs infra health in rollouts. ANSWER OUTLINE: Contrast Canary gradual shift vs Blue/Green instant swap; highlight silent failures, data drift, prediction distribution; cite accuracy and calibration.
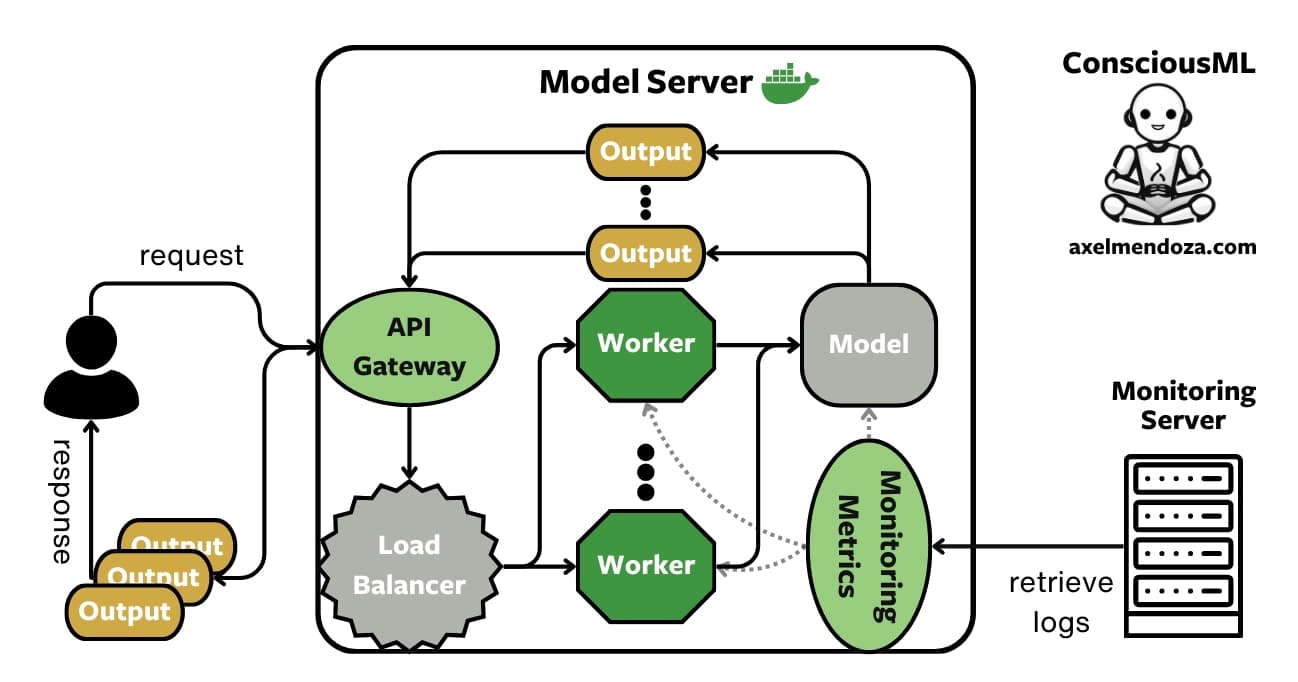
Expose a trained model as a simple web service
Practical MLOps knowledge from model serialization to serving. Package the model into a standard format, containerize it, expose a REST endpoint behind a load balancer, and add monitoring. A bare Flask server without containers or health checks is a red flag.

How would you version control a 50GB dataset in a CI/CD pipeline?
WHAT IT TESTS: Code and data versioning without breaking CI/CD speed. ANSWER OUTLINE: Contrast Git LFS (simple, but 50GB chokes CI clones) with DVC (git metadata plus S3; enables selective pulls and CI cache). RED FLAG: Storing 50GB binaries in Git.

How would GDPR requirements influence experiment tracking and model management design?
WHAT IT TESTS: designing for compliance as a systems constraint, not an afterthought. ANSWER OUTLINE: immutable data lineage, user exclusion lists, audit logs, versioned explainability. RED FLAG: manual deletion without model unlearning or provenance.
How do you ensure ML experiment reproducibility beyond random seeds?
Tests system-level reproducibility through data versioning, environment capture, and pipeline automation. Strong answers cover versioned datasets, containerized dependencies, and immutable experiment logs.

Describe an ML workflow with massive egress fees and re-architecture to mitigate
Tests whether you recognize egress spikes when storage and compute cross cloud or region boundaries. Great answers sketch a multi-cloud training pipeline, cite per-GB rates, and propose caching or compute placement. Red flag: suggesting compression alone.

Design a showback or chargeback system for ML infrastructure costs
WHAT IT TESTS: Bridging ML telemetry with FinOps for shared GPU storage. ANSWER OUTLINE: Tag workloads to cost centers; define shared-resource formulas; automate reconciliation; use showback. RED FLAG: Using raw cloud bills as attribution without GL mapping.
Design a near real-time cost visibility system for ML teams
Tests cost attribution across shared ML infrastructure and streaming pipeline design. Strong answers combine billing exports with resource labels, sub-hour aggregation, and anomaly detection for training spikes.

Describe a basic lifecycle policy to manage cloud storage costs
This tests cost optimization via tiered storage and automated expiration. Strong answers list transitions from Standard to IA to Glacier, then deletion after set days, plus retrieval costs. A red flag is using manual scripts instead of native lifecycle rules.
What is the wrong and right way to manage ML database secrets?
This tests secret management hygiene for ML pipelines. A strong answer rejects hardcoded secrets and env vars, then proposes AWS Secrets Manager with IAM retrieval, TLS, caching, and rotation. A red flag is suggesting .env files, ConfigMaps, or CLI arguments.

Why was this customer denied: global or local explanation?
This tests matching questions to explanation scope. Global methods show overall behavior; local methods explain one prediction. Specific denials need local methods like SHAP. A red flag is using global summaries like permutation importance or PDPs for a case.
How do you give read-only access to a shared cloud storage bucket?
WHAT IT TESTS: Least-privilege IAM for shared data pipelines. ANSWER OUTLINE: Bind an IAM role with read permissions to the team at the bucket level, avoid object-level ACLs, and mount read-only on training VMs.

Propose an architectural solution for contended GPU training resources
Tests multi-tenant GPU scheduling design at scale. Great answers tier jobs by checkpointability, apply quota-based preemption, mix spot and on-demand instances, and use MIG or time-slicing to bin-pack. Red flag: buying GPUs without scheduling logic.