Self-Attention: The Transformer's Core Idea
Self-attention lets a model weigh the importance of different words in a sequence to understand context. This core mechanism of the transformer architecture powers LLMs for translation and generation.
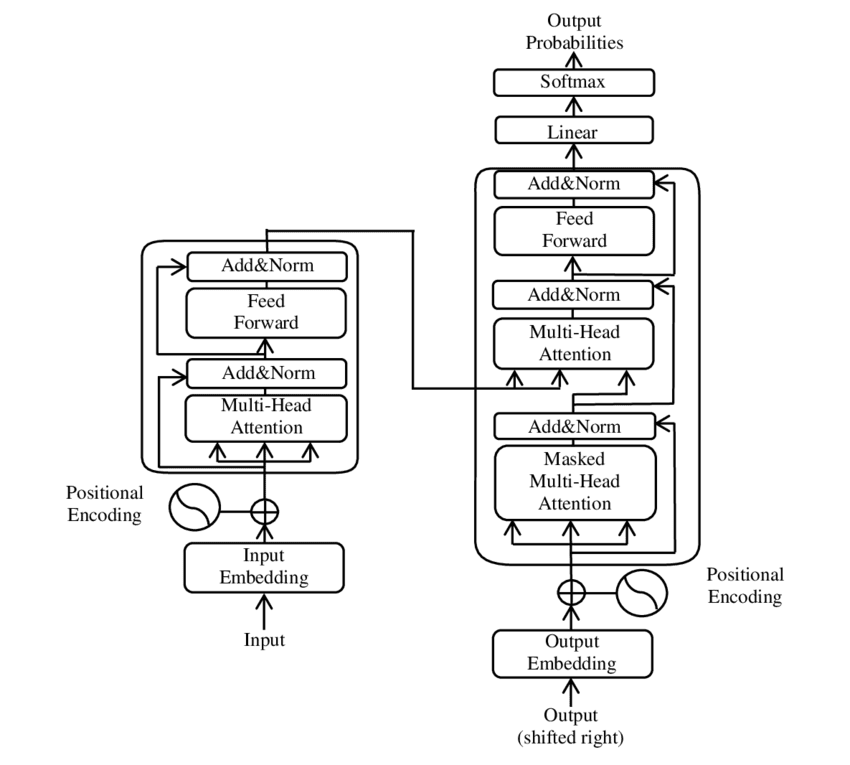
Self-attention lets a model weigh the importance of words in a sequence to understand context, asking "for this word, which other words matter most?" This innovation, from the "Attention Is All You Need" paper, is the core of the transformer architecture that powers modern LLMs. It excels at machine translation and question answering by capturing long-range text dependencies. The footgun is thinking it's a single calculation; multi-head attention runs parallel processes to track distinct relationships like grammar and semantics.
Read the original → Wikipedia: Attention Is All You Need
- #llms
- #transformers
- #self-attention
- #neural-networks
Get five bites like this every day.
Tezvyn delivers a daily feed of 60-second tech bites with quizzes to lock in what you learn.