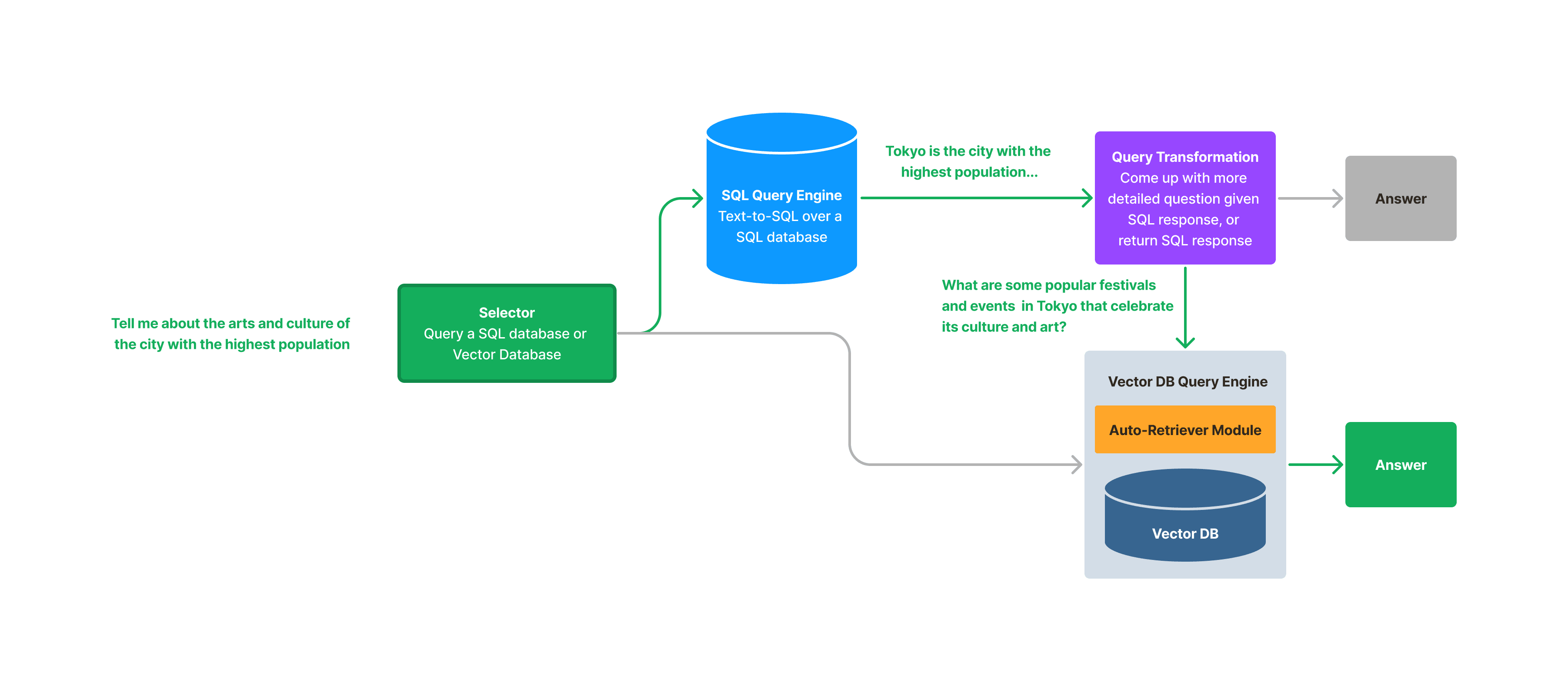
How would you modify retrieval architecture for hybrid text and SQL RAG?
It tests unified retrieval across unstructured text and structured SQL. Outline a query planner that routes to vector search or text-to-SQL, joins the results, and synthesizes a final answer. Never suggest embedding the whole database as text chunks.

Why does your RAG ignore or contradict retrieved context?
Tests separation of retrieval failures from generation grounding in RAG. Strong answers trace symptoms to root causes like bad chunks, prompt ordering, or parametric knowledge override, then outline systematic debugging. Do not just say hallucination.

What does the KL-divergence penalty do in RLHF PPO, and if zeroed?
It tests RLHF reward hacking awareness. The KL penalty anchors PPO to the reference model to stop mode collapse; zeroing it causes over-optimization against the proxy reward model, yielding incoherent outputs.

Walk through RLHF's three stages, outputs, and purposes.
Tests your grasp of the RLHF pipeline end-to-end. A strong answer lists: pretrain an instruction-following LM, train a reward model outputting a scalar preference score, then fine-tune the LM via RL.

Full fine-tuning or LoRA on a tight compute budget?
This tests budget-constrained adaptation for many tasks. A strong answer picks LoRA: it trains only a small number of extra parameters, cutting compute and storage versus full fine-tuning while matching performance.

Describe supervised fine-tuning for a pre-trained language model
Tests if you know SFT aligns a base model to instructions using curated prompt-completion data. A strong answer covers next-token prediction on completions, conversational formats, and small learning rates.
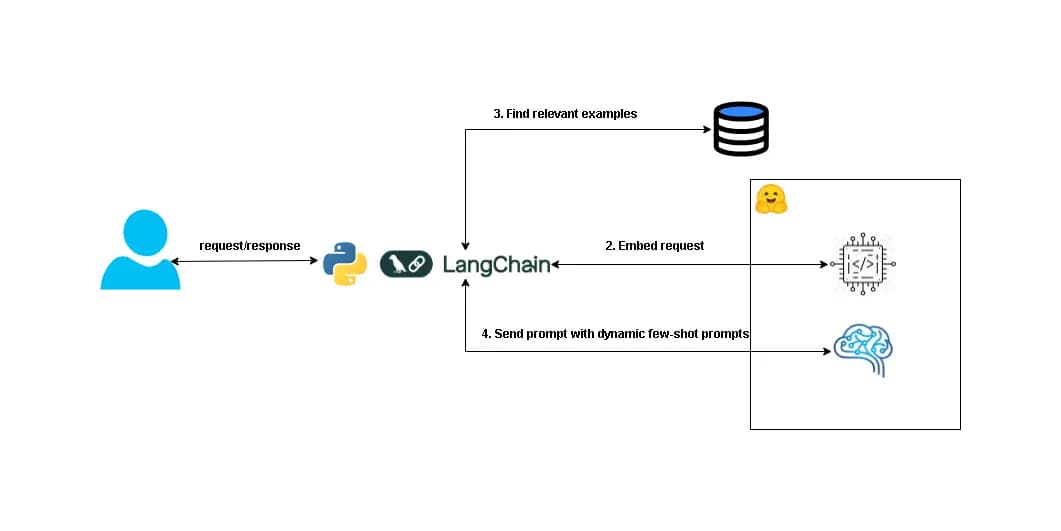
Design dynamic few-shot example retrieval from a vector database
Tests RAG-style prompt engineering with semantic retrieval and latency. Use shared embeddings, approximate nearest neighbors with metadata filters, diversity reranking, and token-bounded prompt templates.

Describe two prompt-based techniques to ensure valid LLM JSON output
This tests output constriction via prompt design. First, embed an exact JSON skeleton with empty values. Second, provide few-shot exemplars mapping inputs to valid JSON. A red flag is suggesting only post-hoc regex repair or larger models.

What causes sudden loss spikes in long pre-training runs?
WHAT IT TESTS: Diagnosing LLM training instabilities under pressure. ANSWER OUTLINE: Name gradient explosions, LR mismatch, FP16 overflow, and poison batches; propose norm checks, rollback, and LR cuts.

Explain data, tensor, and pipeline parallelism and hybrid training strategy
Tests communication and memory tradeoffs of core distributed training strategies. Strong answers contrast data parallelism (shard batch), tensor parallelism (shard layers, all-reduce), and pipeline parallelism (shard stages, p2p), then propose a 3D hybrid…

Why is self-attention O(n^2) and what are the implications?
Tests the attention matrix bottleneck. Strong answers note QK^T yields an N×N matrix, creating quadratic compute and memory that blocks long documents and high-res images. Red flag: confusing model size with activation memory.

Validation loss increases while training loss decreases: what is this?
This tests recognition of overfitting and regularization. A strong answer names it, offers early stopping, dropout or weight decay, and data augmentation or more data. A red flag is suggesting longer training or more parameters without fixing generalization.

Explain word embeddings and why they beat one-hot encoding for large vocabularies
WHAT IT TESTS: dense semantic vectors versus sparse symbolic encodings. ANSWER OUTLINE: embeddings cluster similar meanings in low-dimensional space, while one-hot vectors are orthogonal, huge, and semantically blank.

Google TPU: Built for Matrix Math
A TPU is a specialist ASIC, not a faster GPU; it trades graphics flexibility for matrix-math throughput per watt. Google deploys them for TensorFlow, JAX, and PyTorch at scale. They excel at CNNs but can lag on tasks needing rasterization or recurrent logic.

How do you leverage and fine-tune BERT for niche classification?
Tests transfer learning with scarce labels. Outline: pick a domain-adjacent checkpoint, add a classification head, use learning rates near 2e-5 with early stopping, and stratify tiny validation splits.
What is a word embedding and how does it beat one-hot encoding?
Tests dense semantic vectors versus sparse one-hot representations. A good answer defines embeddings as learned real-valued vectors where similar words are close, contrasts them with orthogonal one-hot vectors lacking similarity, and names Word2Vec or GloVe.

What is Simpson's Paradox and how can it bias A/B tests?
Tests whether you recognize that aggregate trends can reverse within subgroups. A strong answer defines the paradox, gives an A/B example where treatment wins overall but loses in every segment due to skewed allocation, and prescribes stratified analysis.

How do network effects violate A/B tests and how to mitigate them?
Tests SUTVA violations and network experiment design. Answers note treated users alter control outcomes, then propose social-graph cluster randomization to isolate spillovers. Red flag: ignoring peer-to-peer spillover and using user-level randomization.

Why not stop an A/B test when it looks significant early?
Tests whether you understand repeated looks inflate false positives. The term is peeking: checking daily can turn a 5% Type I error rate into roughly 15% by day 3. Red flag: citing "low sample size" without stating that early stopping invalidates the p-value.

P-value vs confidence interval in an A/B test
WHAT IT TESTS: Frequentist reasoning beyond binary significance. ANSWER OUTLINE: A p-value gauges evidence against the null; a 95% CI shows plausible effect sizes and precision. RED FLAG: Calling the CI a 95% probability the true difference is inside.