
How do you diagnose a confounded A/B test with slower page load?
This tests confounding beyond p-values. A strong answer isolates the bug, checks if slower load hurt or helped conversions, and judges whether copy or latency caused the lift. A red flag is defending a 5% win because p < 0.05 while ignoring randomization.

Compare A/B/n testing with multi-armed bandits for headline optimization
WHAT IT TESTS: Grasp of explore-exploit and when rigor beats speed. ANSWER OUTLINE: Contrast A/B/n with dynamic MAB allocation; A/B/n optimizes final inference, MABs optimize reward; flag real-time infra. RED FLAG: Calling MABs always better ignoring regret.

How does cookie clearing affect A/B results and consistency?
This tests bucketing integrity when state changes re-randomize users. Explain that re-bucketing contaminates the sample and triggers SRM; propose deterministic server-side assignment, fingerprinting, or authenticated IDs.
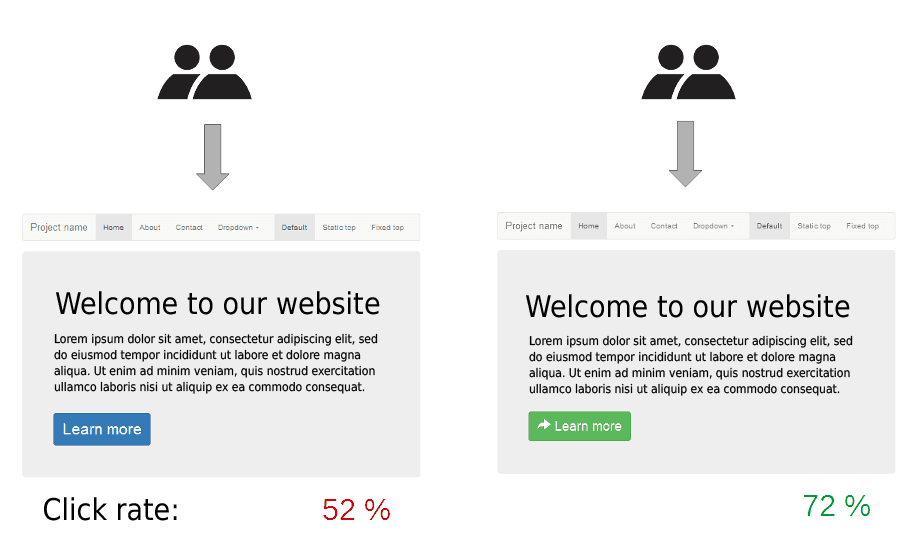
Explain statistical significance in copy A/B tests and why one day fails.
This checks if you distinguish signal from noise. A strong answer defines statistical significance as confidence a difference is real, warns that one-day samples are small and skewed by variance, and cites false positive risk.

Propose a script template and review process for 20 tutorial videos
This tests scalable content ops with distributed engineers. A strong answer gives a modular script template with locked sections, a tiered review pipeline using a style guide and peer review. Red flag: a single flat review or no tone calibration.

How would you script a concurrency analogy for junior developers?
This tests scaffolding hard ideas via ADEPT. A strong answer sequences analogy, diagram, example, plain-English reasoning, and technical notation while flagging where metaphor breaks. A red flag is treating the analogy as proof or ignoring its failure modes.

What techniques make complex technical topics understandable in audio-only podcasts?
WHAT IT TESTS: Instructional design for audio working memory. ANSWER OUTLINE: Great answers cite relatable analogies, vocal signposting, and narrative framing without visual references. RED FLAG: Relying on show notes or telling listeners to look it up later.

How do you convert dense documentation into a spoken video script?
WHAT IT TESTS: Auditory versus visual processing. A GOOD ANSWER COVERS: shorter sentences, inline context instead of footnotes, conversational second-person voice, verbal signposts, and visual cues.

Design a CI/CD step to auto-lint application content
WHAT IT TESTS: Operationalizing content quality gates in CI/CD. A GOOD ANSWER COVERS: rule types (terminology, placeholders, i18n), tools (TextLint, Vale, AST), and failure mode (block vs warn). RED FLAG: Treating it as post-deploy check or spell-check.

Describe architecture for live UI text updates without deployment
WHAT IT TESTS: headless CMS design and cache invalidation for live content. ANSWER OUTLINE: structured API, webhook sync, client or edge rendering with cache versioning, and rollback. RED FLAG: direct DB writes from the browser or ignoring CDN stale cache.
How do you implement a CTA A/B test and attribute conversions?
This tests experiment architecture from bucketing to attribution. A strong answer covers: stable user bucketing, server or client-side rendering, and conversion events tagged with experiment and variant IDs.

How would you implement specific error messages for failed validation rules?
WHAT IT TESTS: Architecting validation as structured data instead of booleans. A GOOD ANSWER COVERS: error codes from validators, a mapping layer separating logic from copy, and accessible inline rendering.
How would you model cross-platform ad campaign data and adaptation logic?
WHAT IT TESTS: Separating campaign intent from platform execution. ANSWER OUTLINE: Propose a canonical model, platform adapters mapping copy to each schema, and an async pipeline with validation.

How would you implement a multi-armed bandit for real-time ad optimization?
WHAT IT TESTS: System design balancing exploration and reward. ANSWER OUTLINE: Use Thompson Sampling or UCB1; split low-latency inference from async updates; track regret. RED FLAG: Epsilon-greedy without Bayesian updates, delayed feedback, or scaling.

Design a simple templating system for ad copy generation
Tests separation of concerns and API design. A good answer: data model separate from template, placeholder syntax, graceful missing-value handling, and HTML escaping. Red flag: naive string concatenation without validation or extensibility.

Design a database schema for an ad A/B test
Tests separating high-volume events from slow-changing experiment metadata. Strong answer: distinct tables for variants, impressions, and clicks; clicks link to impressions; a user-assignment table avoids duplicating variant data per event.

Build a system to send 1M personalized emails in 2 hours
This tests async distributed throughput and deliverability. Cover partitioned queues, auto-scaling workers, per-ESP rate limits, IP rotation, and exponential backoff with dead-letter queues. Red flags: synchronous sends, skipping IP warmup, or no retry logic.
Architect email subject line A/B testing for a large user base
Tests distributed systems and statistical rigor. Covers deterministic user bucketing, isolated variant delivery, deduplicated tracking, and pre-powered significance. Red flag: daily re-randomization or using open rate without confidence intervals.

How would you design an idempotent order confirmation email sender?
Tests preventing duplicate side effects in distributed systems. Strong answers use deduplication keys, idempotency windows, and distinguish client retries from broker redelivery. Red flag: using a read-before-write check without unique constraints or TTLs.
How would you programmatically populate an HTML email template?
WHAT IT TESTS: Clean separation of data and presentation plus safe rendering. ANSWER OUTLINE: Pick a template engine, bind the user object as context, render HTML, and send via a mailer.