
How would you design resumable multi-step onboarding state management?
This tests cross-device onboarding resume. A strong answer uses debounced server sync for cross-device resume with localStorage fallback, covers anonymous users, and handles conflicts. Red flag: pure client or server storage ignoring offline gaps or privacy.

How would you validate that early Project creation drives retention?
Tests causal rigor on behavioral predictors. Good answer: define D30 retention and the 24-hour treatment; pull timestamps and covariates; cohort-compare with propensity matching; show lift with confidence intervals and propose an A/B nudge.

How do you determine if a user is 'new' for a setup guide?
This tests whether you separate account age from user state for onboarding. Good answers compare created_at (brittle) with a persistent flag (idempotent) and consider milestones. A red flag is using a timestamp as a permanent new proxy without managing reruns.

Design a programmatic SEO system for 1 million landing pages
Tests data infrastructure thinking, not content generation. Covers one-row-one-page schema, template rendering with edge caching, hierarchical routing, and crawl-budget controls via sitemaps. Red flag: AI bulk writing without structured data or caching.

Architect an A/B test for paid-ad signup flows
Tests pre-auth bucketing and funnel attribution. Hash a stable anonymous ID for fast assignment; stream events via Kafka into hourly aggregates; run t-tests on signup rates. Red flag: assigning after signup starts or DB lookups per assignment.

How would you implement a last-touch attribution model for user signups?
Tests your ability to translate marketing concepts into warehouse SQL. A strong answer covers UTM/pageview events, sessionized tables, and a windowed join for the last touch within 30 days of signup.

What is the multiple comparisons problem and how to correct?
This tests your grasp of family-wise error inflation across many tests. A strong answer defines the problem, contrasts per-comparison and family-wise error, and names corrections like Bonferroni or FDR.

How do you set up a button color A/B test?
Tests whether you can define a valid experiment, not just a color change. A strong answer covers hypothesis, randomization, primary metric, sample size, and significance threshold.

WAU is flat despite positive A/B tests; why and how to diagnose
This tests distinguishing real impact from statistical artifacts. Strong answers cite false positives from low base rates, peeking, novelty, and local-global mismatches. Diagnose with long-term holdouts, audits, and causal bridges.
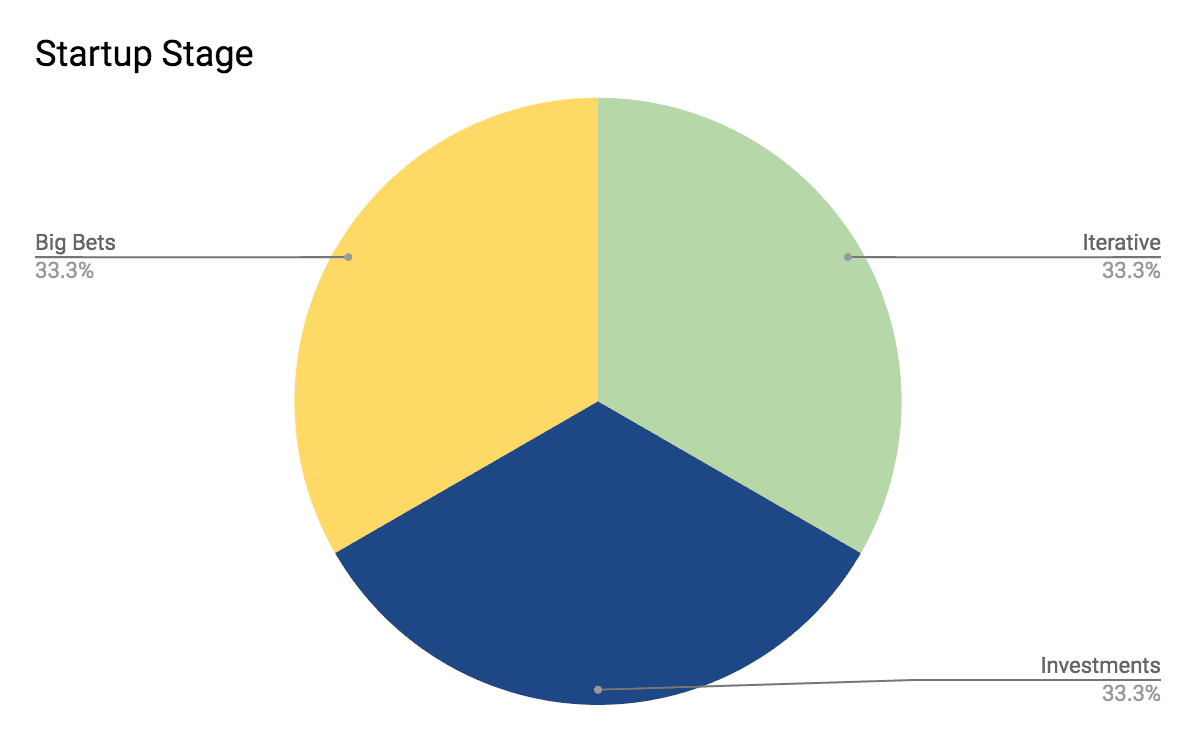
How would you structure your growth team's experimentation portfolio?
WHAT IT TESTS: Capital allocation across risk classes in growth. ANSWER OUTLINE: 3 asset classes (iterative 30-70%, tech investments, big bets 20-40%), use expected value per week, and evolve the mix. RED FLAG: Gut voting or flat effort without expected ROI.

Develop a testable hypothesis for a 40% email verification drop-off
This tests structured hypothesis formation under uncertainty. Strong answers: segment the 40% drop by device and latency; build a Customer Theory from data; isolate one lever; draft a four-part MECLABS hypothesis. Red flag: skipping diagnosis to guess fixes.

What framework decides between low-effort/low-impact and high-effort/high-impact experiments?
This tests structured experiment sequencing beyond gut instinct. A strong answer picks ICE, RICE, or PIE; scores both experiments by impact, confidence, and effort or reach; then weighs opportunity cost and bandwidth.

Which three data sources would you analyze to improve activation?
This tests whether you ground hypotheses in diverse evidence before experimenting. A strong answer names qualitative feedback, funnel metrics, and behavioral analytics as distinct inputs.

Design the data model and backend for a 7-day trial at scale
Tests state machine design for time-bound entitlements at scale. A strong answer covers: an idempotent enrollment API, a trial ledger with timezone-aware expiration, and an event-driven expiration pipeline.

Design a variable daily-login reward system with anti-gaming controls
Tests server-side reward probabilities and idempotency in distributed systems. Strong answers cover: configurable weights, idempotent tokens with DB unique constraints, rolling windows, and server-side grants.
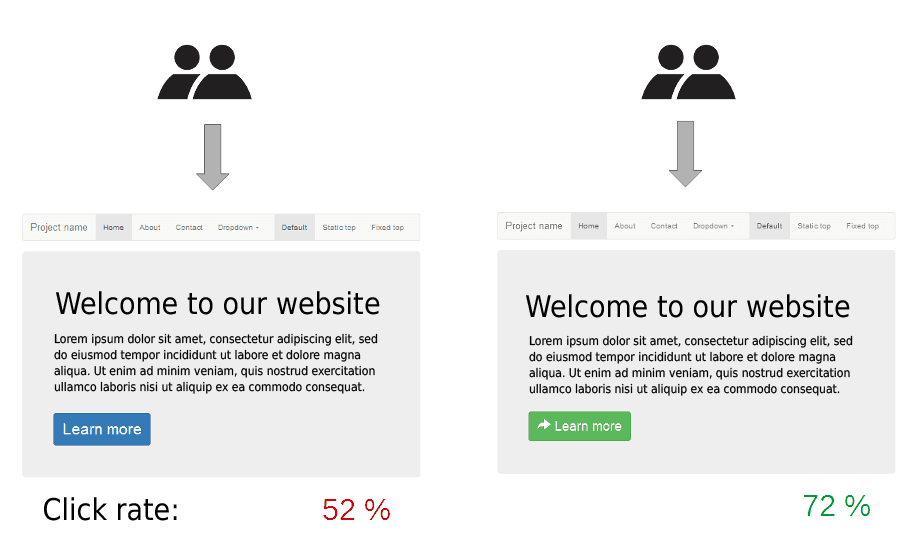
Design an A/B test for loss aversion versus gain framing at checkout
Tests whether you can isolate framing effects from checkout confounders. Strong answers detail user-level randomization, event logging, and guardrail metrics like revenue per visitor. Red flag: a conversion-only analysis with no unit of diversion defined.

How would you implement a timezone-safe, tamper-proof offer countdown?
Tests distrust of the client and server-side UTC enforcement. Outline: server owns canonical end time; client syncs clock offset to render remaining time; checkout re-validates expiry. Red flag: using local Date.now or localStorage.

What causes client order_completed events to diverge from backend records?
Tests end-to-end event reliability. Separate client failures (network, ad blockers, duplicates) from backend gaps (idempotency, validation, races) and propose timestamped join analysis. Red flag: blaming users or fixing before measuring gap direction.

What is a conversion funnel? Instrument a three-step onboarding funnel with events.
This tests translating business funnels into concrete event instrumentation. A strong answer outlines three ordered steps, names exact events like user_signed_up and project_created, and notes unique-user counting.

Describe the architecture for multi-touch attribution with time-decay
WHAT IT TESTS: Architecture for identity resolution and multitouch attribution. ANSWER OUTLINE: Stitch IDs, stream events to warehouse, sessionize journeys, then apply decay weights in SQL.