
How would you implement a simple box blur on a grayscale image?
WHAT IT TESTS: Spatial convolution and image filtering basics. ANSWER OUTLINE: Iterate interior pixels, sum the N by N neighborhood, divide by kernel area, write to a new buffer. RED FLAG: In place updates that blur already blurred values.

Describe the BRDF, its advantage over Lambertian, and critical CV tasks
Tests 4D view-dependent reflectance. Strong answers define BRDF as dL_r/dE_i (sr^-1) over four angles; note Lambertian is isotropic; cite photometric stereo and shape-from-shading where specularity breaks the model. Red flag: calling it albedo.
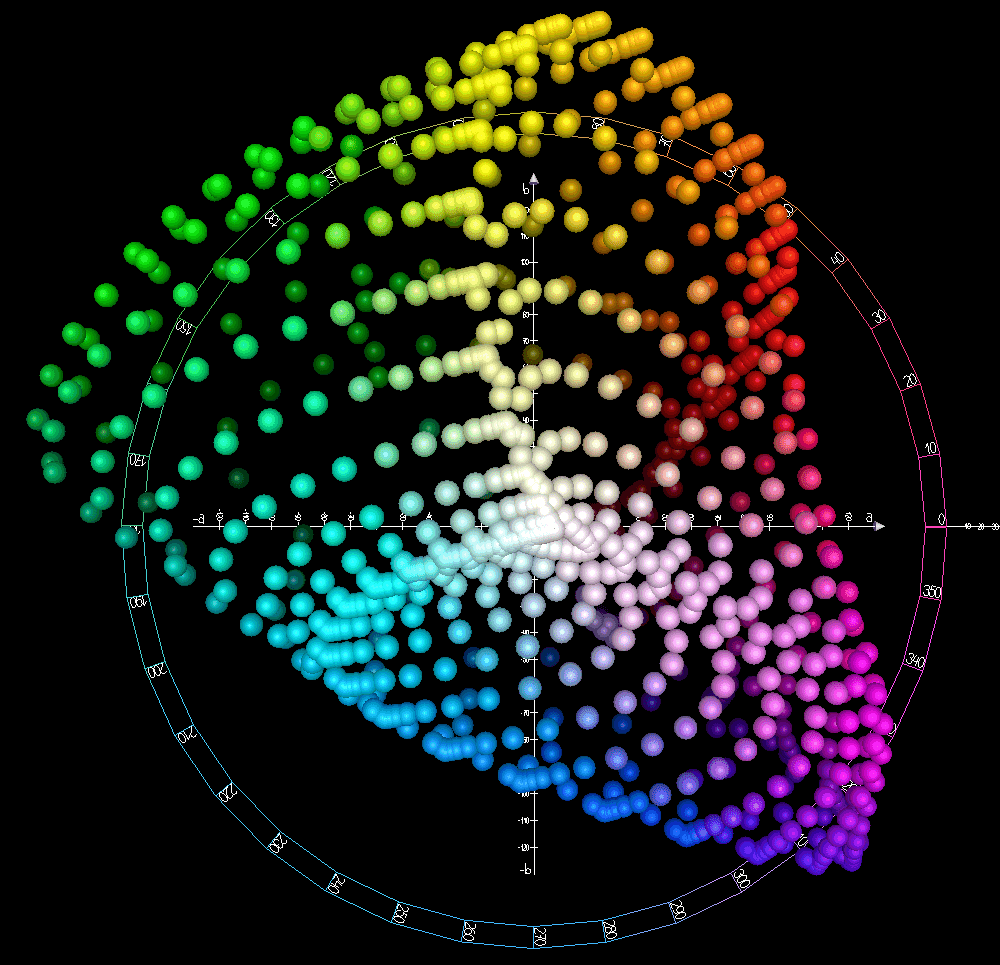
Why is RGB Euclidean distance a poor measure of perceptual color difference?
This tests perceptual uniformity. A good answer explains that RGB distance does not match human vision, then describes CIELAB as a space where deltas approximate perceived differences, making segmentation align with human vision.

Compare YCbCr and RGB. Why chroma subsampling for compression?
Tests color decorrelation and perceptual redundancy. Contrast correlated RGB with YCbCr's luma-chroma split; eyes resolve brightness better than color, so 4:2:0/4:2:2 cuts chroma bandwidth ~50-75% with little loss.

Explain the pinhole camera model and intrinsic matrix K
Tests projective geometry and mapping sensor properties to K. Good answers derive perspective projection via similar triangles, list fx, fy, cx, cy, skew, and explain pixel scaling. Red flag: mixing intrinsics with extrinsics or saying K includes distortion.

Describe a grayscale histogram and its use in exposure and equalization
Tests pixel distribution intuition. A strong answer covers intensity bin counts, left or right clustering for exposure errors, and CDF-based redistribution for equalization. Red flag: calling equalization min-max stretching without cumulative mapping.

What is the difference between lossy and lossless image compression?
This tests irreversible discard versus perfect reconstruction. A strong answer defines lossy as dropping detail, lossless as fully reversible, names JPEG, PNG, and chooses lossless for masters, lossy for web. Red flag: claiming lossless is always smaller.

MLOps: When to Build vs. Buy Your Infrastructure
Deciding to build or buy MLOps tools hinges on whether it creates a competitive advantage. For commodity tasks like experiment tracking, buying a managed service avoids locking up engineers.

Data Storage Tiering: Pay Only for the Access You Need
Treat data like items in a house: hot, frequently used data on the counter; cool, less-used data in the pantry. Cloud providers use this to price storage, letting you move old logs to cheaper tiers.

Unit Economics: Tying ML Costs to Business Value
Unit economics connect your ML spending to business outcomes. Instead of a total cloud bill, you see cost per prediction or per token. This helps product owners make pricing tradeoffs and engineers spot efficiency gains.
Cloud Cost Allocation: Making Teams Own Their Spend
Cloud cost allocation answers "who pays for what?" by assigning every dollar of your cloud bill to a team or project. It uses metadata like tags and account structures to create showback reports.

FinOps: Making Cloud Costs Everyone's Job
FinOps makes cloud cost a shared responsibility between engineering, finance, and business teams. It applies the variable, on-demand nature of the cloud to financial accountability.
Counterfactual Explanations: How to Change a Model's Mind
A counterfactual explanation finds the smallest input change that flips a model's prediction. It's used to give actionable feedback, like telling a user what to change to get a loan approved.
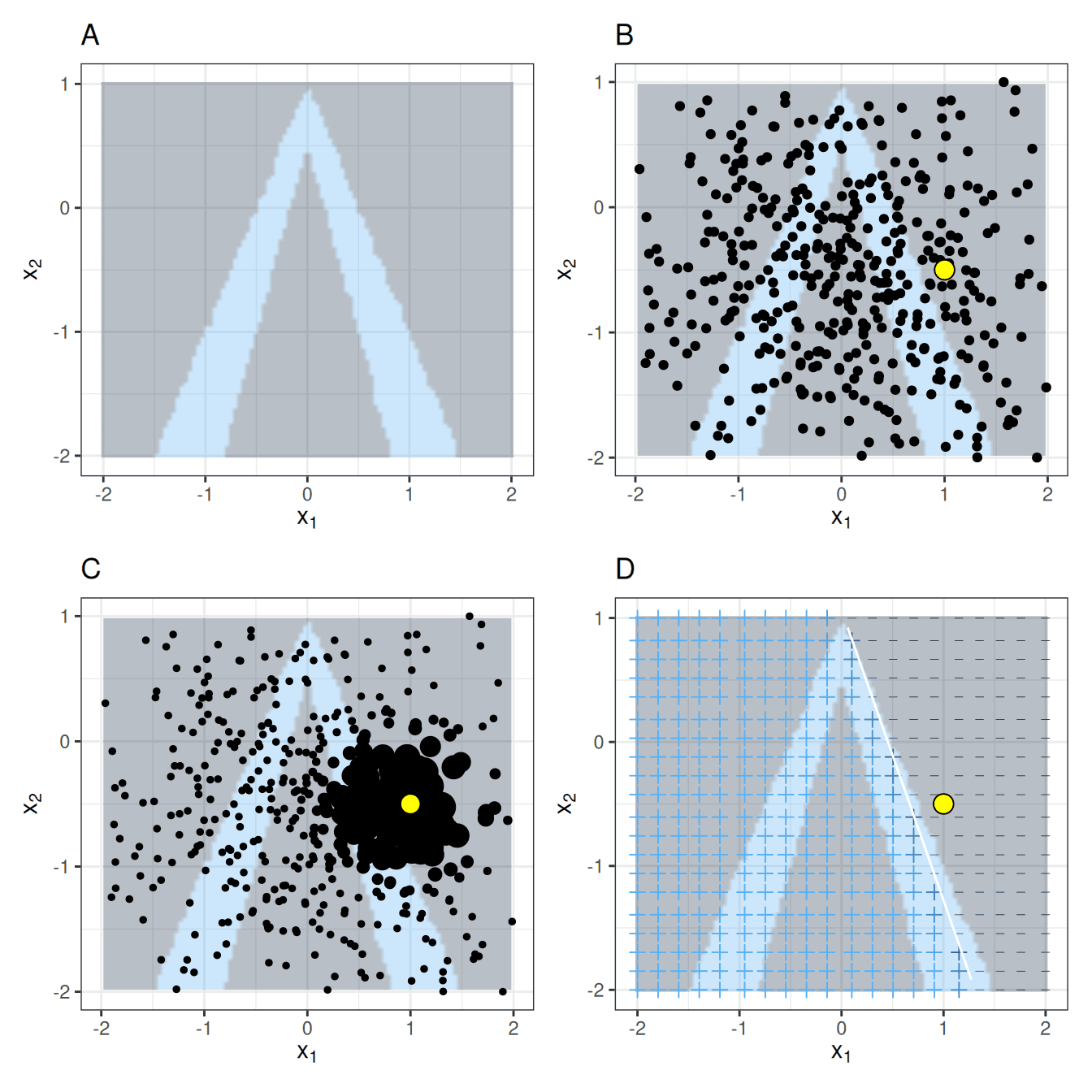
LIME: Explaining Single Predictions from Any ML Model
LIME explains a single prediction from any 'black box' model by approximating it with a simpler model that's only accurate locally. Use it to see why a specific user churned.
ML Threat Modeling: Assume Your Data Is Compromised
Threat modeling for ML means assuming your training data is already compromised. This is crucial for services using public or user-supplied datasets. The main footgun is trusting data sources, as data poisoning can silently corrupt your model's behavior.

Model Interpretability vs. Explainability
Interpretability means a human can grasp a model's logic (e.g., a simple decision tree). Explainability is stronger: it's about why the model made a *specific* choice. This is key for debugging or justifying high-stakes decisions.

Hybrid Cloud MLOps: Train Anywhere, Deploy Everywhere
Treat your ML infrastructure like your applications—a consistent platform that runs anywhere, avoiding siloed stacks for data science and app dev. Use it to train on cloud GPUs but deploy on-prem for low latency, ensuring dev/prod parity across environments.
The MLOps Maturity Model: A Roadmap for Growth
The MLOps Maturity Model is a roadmap from manual chaos to automated ML systems. Use it to assess your team's current state and plan incremental improvements.
MLaaS: Your Machine Learning Lab in the Cloud
Machine Learning as a Service (MLaaS) provides the key ingredients for ML—data, compute, and expertise—as a cloud service. This lets teams build models for forecasting or spam detection without buying expensive hardware.

PaaS: The Managed Platform for Building Applications
PaaS gives you a ready-to-use development environment, handling the OS and middleware so you can just code. It's used to accelerate app development for web, IoT, or ML. The main footgun is vendor lock-in, making future platform migrations difficult.