
Pipeline Step Caching: Don't Recompute What You Don't Have To
Pipeline step caching is memoization for your ML infrastructure, saving time and money by reusing previous results. It's used in MLOps pipelines when inputs and code haven't changed. The footgun: the cache is scoped to one pipeline and a timeout, not globally.
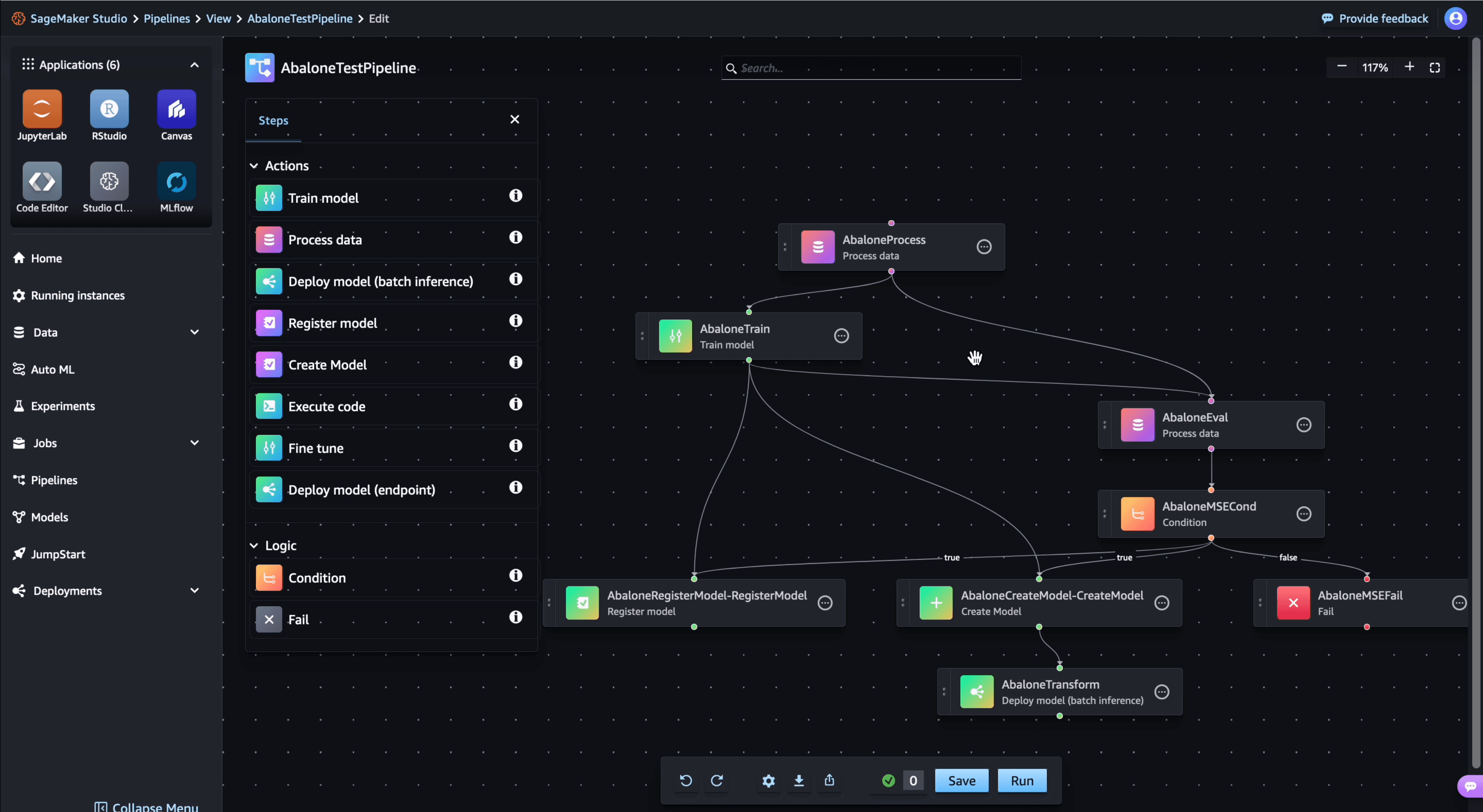
Amazon SageMaker Pipelines: Repeatable ML Workflows
Think of SageMaker Pipelines as a CI/CD pipeline for ML models, automating workflows from data prep to deployment. Use it for reproducible training and automated retraining.

Population Stability Index (PSI): Quantifying Data Drift
The Population Stability Index (PSI) gives you a single number to quantify data drift between training and live data. It's used in MLOps to monitor model health, especially in finance. The footgun is ignoring a high PSI, which signals silent prediction decay.
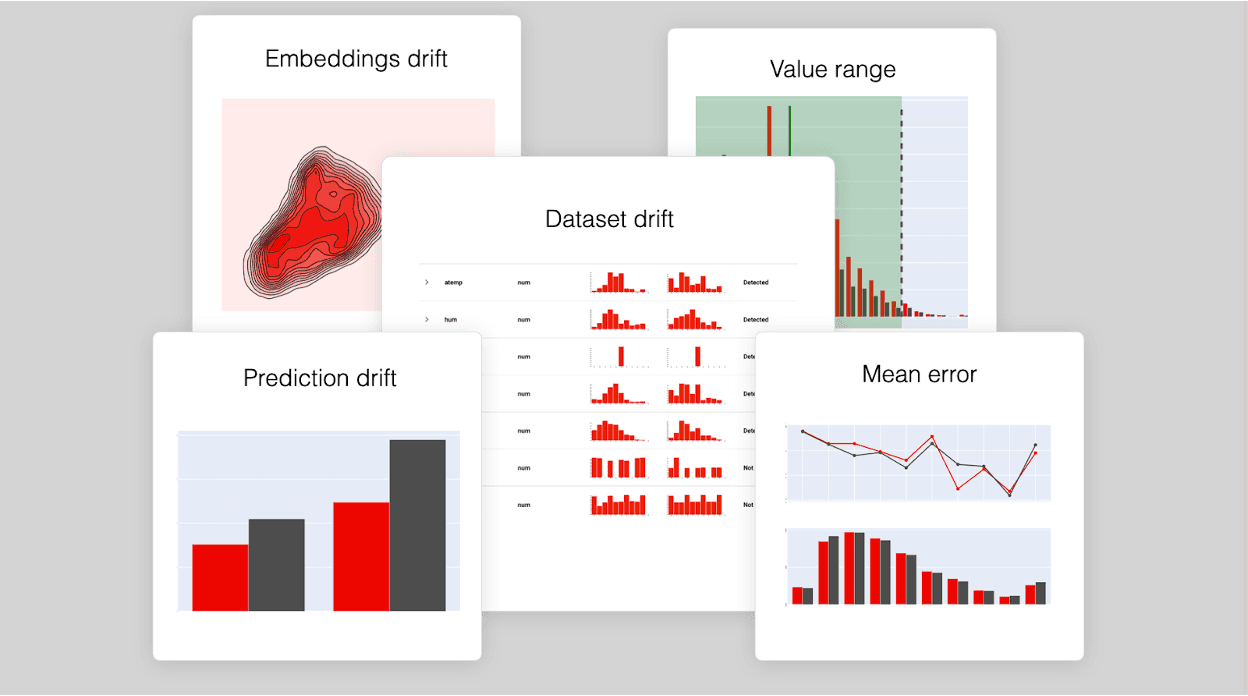
ML Monitoring Dashboards: Your Model's Health Chart
An ML monitoring dashboard is a health chart for your production model, showing how its performance decays. It tracks silent failures like data drift or concept drift, where user behavior changes and makes your model obsolete.

Autoscaling ML Inference Endpoints
Autoscaling matches your ML model's compute to real-time demand, like an elastic container for your inference service. It handles spiky traffic for online endpoints, scaling up for peaks and down to save costs.

Inference Batching: Grouping Requests for Throughput
Think of inference batching as a carpool for your ML model. Instead of sending each request in its own car, you wait a few microseconds to fill a bus, dramatically improving GPU efficiency.

TorchServe: Serving PyTorch Models in Production
TorchServe is a web server for your PyTorch models, turning them into production-ready API endpoints. It's used to expose trained models over a network via REST or gRPC for inference, handling batching and multi-model serving.
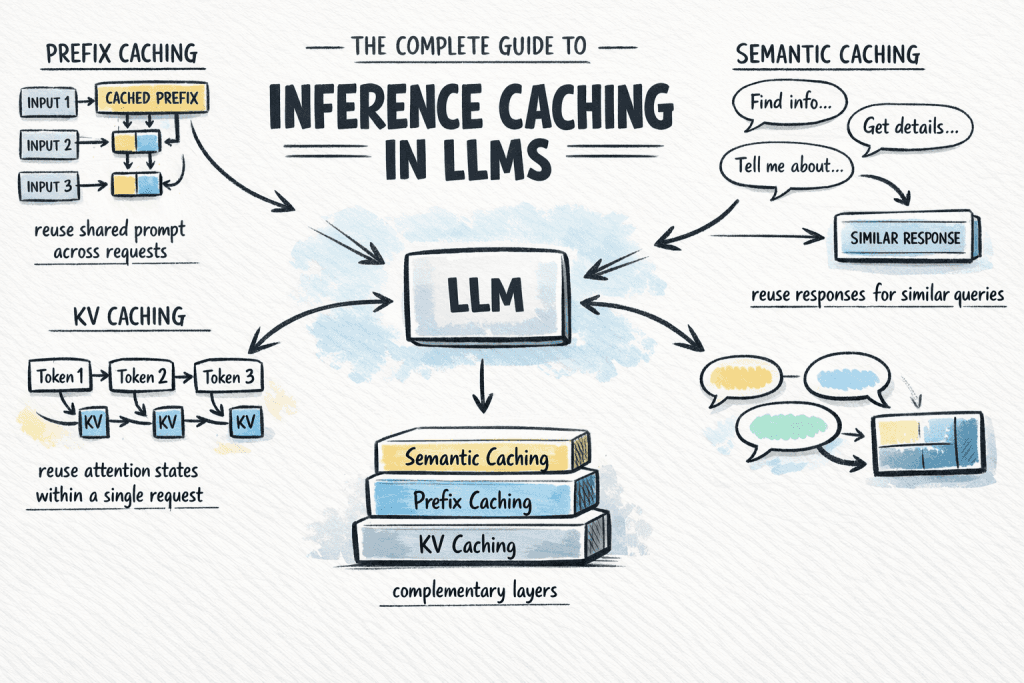
LLM Inference Caching: Pay for Computation Once
LLM inference caching reuses past computations to cut costs and latency. It avoids reprocessing shared system prompts or serves full answers for common queries without hitting the model. The footgun: semantic caches can return a "similar" but incorrect answer.

Git-Based CI Triggers: Automating on Events
Think of Git events like `push` or `pull_request` as the "play" button for your automation. This is how CI systems automatically run tests on new code. The footgun is using broad triggers, like `push` on all branches, which causes costly and redundant runs.
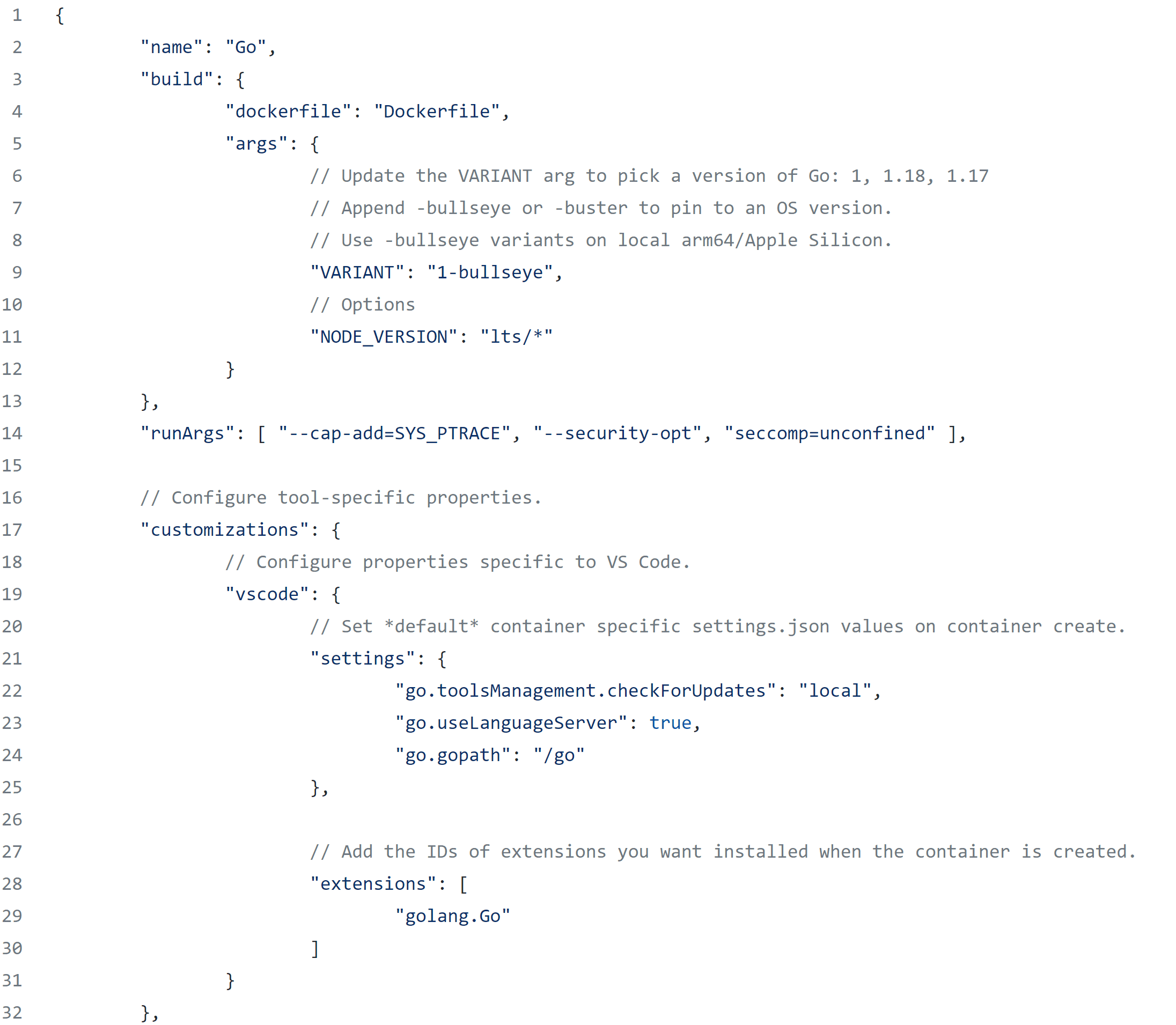
Dev Containers: Your Dev Environment as Code
A dev container packages your entire development environment—tools, libraries, and settings—into a single, portable container. Use it to standardize team environments, simplify onboarding, and ensure consistency between local dev and CI.

Python Virtual Environments: Isolate Project Dependencies
A Python virtual environment is a self-contained directory with its own Python interpreter and packages, preventing dependency conflicts between projects. The biggest mistake is checking the environment folder into source control; it's disposable and meant to…

Great Expectations: Unit Tests for Your Data
Great Expectations brings unit testing to your data, letting you assert what a dataset should look like. It validates data within a pipeline, preventing bad data from corrupting models or reports.

CD4ML: Automating ML from Data to Deployment
CD4ML extends CI/CD to manage ML's three axes of change: code, data, and models. It automates the entire lifecycle, enabling reliable updates for systems like sales forecasting.

Dynamic Batching: Balancing LLM Throughput and Latency
Dynamic batching groups LLM requests like a bus that leaves on a schedule or when full, whichever comes first. This improves throughput in inference servers by avoiding long waits. The footgun: all requests in a batch are still held hostage by the slowest one.

Model Pruning: Making LLMs Smaller, Not Dumber
Model pruning is surgical weight loss for an LLM, removing neurons or layers to reduce its size. It's used to create smaller, faster versions of models like LLaMA for efficient deployment. The footgun: naive pruning can cripple the model's core capabilities.

Modality Gap: When Multimodal LLMs Don't Trust Their Senses
A multimodal LLM has a modality gap when it trusts one input type (like text) over another (like images), even with identical information. This bias causes performance drops, like ignoring visual data if conflicting text is present.

Full Fine-Tuning: Updating Every Model Parameter
Full fine-tuning updates all weights of a pre-trained model on your new data, unlike methods that only change a small fraction. Use it to deeply embed new knowledge, but beware: it's costly and risks making the model forget its original general skills.
Cross-Encoder Re-ranking: Accuracy Over Speed
A cross-encoder re-ranks search results by reading the query and each document together, allowing it to spot subtle connections. It's the second, high-precision step in a search pipeline, re-ordering a small list of candidates.

Mixture of Experts: Scaling Models by Activating Specialists
A Mixture of Experts (MoE) model acts like a team of specialists instead of one generalist. A router sends each token to a few expert sub-networks, enabling faster training and inference for massive models.

The Llama Model Family: Open-Source AI for Production
Think of Llama not as one model, but a family of open-source AIs you can run anywhere. Use it for cost-effective, fine-tuned applications like internal search or when you need full control. The biggest mistake is mis-sizing the model for your task.