
Hugging Face Hub: The GitHub for Machine Learning
Think of the Hugging Face Hub as the GitHub for machine learning. It's a central platform to find, share, and collaborate on millions of models, datasets, and demo apps. Use it to download a pre-trained model or share your own.

The EU AI Act: Risk-Based AI Regulation
The EU AI Act isn't a blanket ban but a risk-based framework. It sorts AI into tiers—from unacceptable to minimal risk—and applies rules proportionally, affecting any company with AI users in the EU. The footgun is assuming it only applies to EU companies.

Fairness Metrics: Quantifying AI's Impact on People
Fairness metrics translate "fairness" into a measurable score, checking if a model treats groups equitably. They are crucial for models in hiring or lending.

vLLM: Faster LLM Inference with PagedAttention
vLLM is a serving engine that speeds up LLM inference by treating GPU memory like virtual memory. It's used to serve models with higher throughput by batching requests without wasting memory on padding.

FlashAttention: Faster, Memory-Efficient Exact Attention
FlashAttention is an IO-aware algorithm that computes exact attention faster and with less memory. It avoids slow GPU memory transfers, making it a key optimization for training and serving large models on modern GPUs.

ONNX Runtime: Run Any AI Model, Anywhere
ONNX Runtime is a universal engine for AI models, letting you run them efficiently on any hardware, from cloud GPUs to a user's browser. It's used to deploy models for fast inference on servers or mobile devices.

Post-Training Quantization: Shrink Models Without Retraining
Post-Training Quantization (PTQ) shrinks a pre-trained model by converting its weights to lower precision, like turning a WAV file into an MP3. Use it to run large models on consumer GPUs without costly retraining.

Model Cards: The 'Nutrition Label' for AI Models
A model card is the nutrition label for an AI model, summarizing its ingredients, intended use, and risks. Found in model repos, it details training data, performance, and ethical guardrails.

Human Evaluation: Judging AI When Metrics Aren't Enough
Human evaluation is the ultimate reality check for AI, using people to judge qualities like fluency and coherence that automated scores can't capture. It's essential for tasks like summarization but is too slow and costly to use for everything.

BLIP: Bootstrapping Better Vision-Language Models
BLIP is a pre-training framework that masters both image understanding and generation by creating its own training data. It uses a captioner and filter to generate clean image-text pairs from noisy web data.

LLMs Get 'Lost in the Middle' of Long Contexts
LLMs struggle to find information buried in the middle of long prompts. Performance is highest when key facts are at the beginning or end of the context. This impacts multi-document QA and RAG.
Hybrid Search: Combining Keyword and Vector Search
Hybrid search combines keyword precision with vector search's conceptual understanding in one query. It excels at retrieving relevant documents for RAG by finding both exact matches (like names) and similar ideas.

Dense Passage Retrieval (DPR): Semantic Search for QA
DPR finds answers by meaning, not just keywords. It converts questions and documents into vectors and finds the closest matches, forming the core of Retrieval-Augmented Generation (RAG).

Reward Modeling: Teaching an LLM What 'Good' Means
A reward model is a judge that scores an LLM's outputs based on human preferences. It learns to assign a numerical 'goodness' score to text, turning subjective quality into an optimizable signal for training models like ChatGPT.

PEFT: Fine-Tune Large Models on a Budget
Parameter-Efficient Fine-Tuning (PEFT) adapts huge models without retraining everything. It's like adding a task-specific cheat sheet to a genius brain. Use it to specialize LLMs on consumer GPUs.
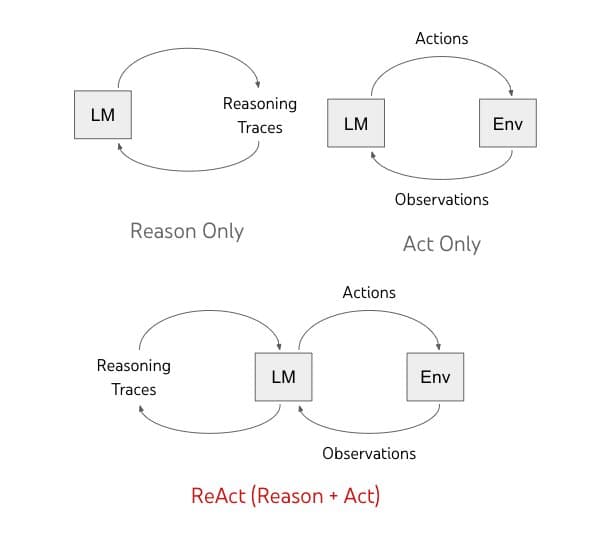
ReAct: Teaching LLMs to Think, Act, and Observe
ReAct teaches an LLM to solve problems by interleaving thought, action, and observation. This is key for agents that search the web or query APIs to answer questions with external data.

Tensor Parallelism: Split Layers, Not Just Models
Tensor Parallelism splits a single large model layer, like a weight matrix, across multiple GPUs to run in parallel. This is crucial for inference with models whose layers exceed a single GPU's VRAM.

Pipeline Parallelism: An Assembly Line for Your Model
Think of training a huge model like an assembly line. Pipeline parallelism splits a model's layers into stages across multiple GPUs, allowing you to train models too large for one device.

Data Parallelism: One Task, Many Data Chunks
Data parallelism splits a huge dataset across multiple processors, each running the same task on its own chunk. It's how large models are trained on massive datasets, with each GPU handling a different batch of data.

Common Crawl: A Free Snapshot of the Entire Web
Common Crawl is a public library of the internet—a massive, free snapshot of web text and links. It's the raw material for training many LLMs and for academic research on web-scale data. The footgun: it's unfiltered, containing everything from facts to spam.