
Track an 'Export to CSV' button's usage
This tests modeling a feature's full lifecycle (intent, success, failure) in analytics. Propose one custom event like `export_interaction` with a `status` parameter ('success', 'failure') fired on completion, not just on click.
Design a Near Real-Time Analytics Pipeline
Tests your ability to design a low-latency data system and articulate trade-offs. A good answer covers ingestion (Kafka), processing (Flink), storage (Druid), and visualization (Grafana), contrasting the architecture's low latency with a batch setup.
Optimizing a Slow, Expensive Data Warehouse for BI Dashboards
Tests your grasp of data warehouse architecture beyond basic SQL. A great answer covers partitioning/clustering, materialized views for pre-aggregation, and cost controls. A red flag is suggesting only query rewrites or just 'adding more compute'.

Describe the role of dbt in a modern analytics stack
Tests your grasp of modern ELT patterns. A good answer explains how dbt uses SQL for in-warehouse transformations, enabling software engineering practices like version control and testing. A red flag is confusing dbt with a full ETL tool or an orchestrator.

Describe tracking a user event from frontend to BI tool
Tests your grasp of the modern data stack. A great answer outlines the five stages: frontend emission, ingestion, loading into a warehouse, transformation, and BI visualization. A red flag is describing only the frontend code and ignoring the data pipeline.

Correlate API Slowness with User Engagement
This tests your ability to design a controlled experiment and join disparate data. A good answer outlines an A/B test with an artificial delay, logging with shared IDs, and statistical analysis. A red flag is proposing a purely observational study.
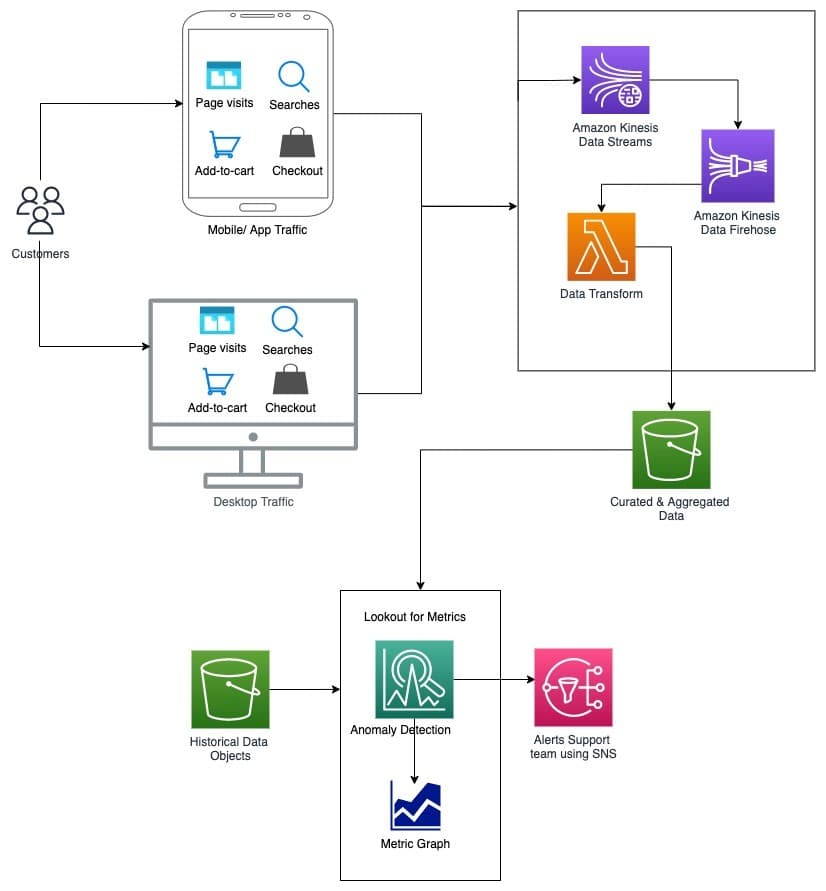
Design a Real-Time Anomaly Detection System for E-commerce Events
This tests your ability to design a real-time data pipeline and apply ML to a business problem. Outline a streaming architecture (e.g., Kinesis), processing, and storage.

Describe two methods for generating prediction intervals
This tests your grasp of uncertainty quantification. A great answer contrasts an analytical method (assuming normal errors, using multipliers like 1.96 for 95%) with a simulation method (bootstrapping residuals).

Which model for forecasting with seasonality and trend?
This tests your knowledge of classical time series models. A good answer names Holt-Winters, explaining its level, trend, and seasonal components. It also discusses choosing between additive and multiplicative methods. A red flag is jumping to complex models.
Train-Test Split vs. Time-Series Cross-Validation
This tests your grasp of data leakage in temporal data. A good answer explains why random splits create lookahead bias, then details how rolling-origin validation respects time. A red flag is just describing methods without explaining *why* one is necessary.
How would you measure a sales forecast model's accuracy?
Tests if you can link statistical metrics to business outcomes. Define MAE (average error) and RMSE (penalizes large errors). Choose RMSE when large misses are costly (e.g., stock-outs), MAE otherwise. A red flag is reciting formulas without business context.

How CUPED increases statistical power in experiments
Tests your grasp of variance reduction in A/B testing. Explain how CUPED uses correlated pre-experiment data to reduce outcome variance, increasing statistical power. A red flag is confusing it with simpler difference scores, which can actually increase noise.

Primary vs. Guardrail Metrics in Experiments
Tests your grasp of risk management in A/B testing. A great answer defines a primary metric as the goal and a guardrail as a 'do no harm' check. A feature ships only if the primary improves without hurting guardrails.

Why is stopping an A/B test early problematic?
Tests understanding of the 'peeking problem' in A/B testing. A good answer defines peeking, explains how it inflates false positive rates, and contrasts it with waiting for a pre-determined sample size. A red flag is not explaining the statistical mechanism.
Explain Simpson's Paradox with a user engagement example
Tests if you see beyond aggregate data. Define the paradox, give a numerical example where a feature fails overall but wins in segments (e.g., new vs. returning users), and name the confounding variable. A vague definition without numbers is a red flag.
Mean vs. Median for API Response Times?
Tests your understanding of non-normal distributions like latency. Choose median as it's robust to outliers that skew the mean. Then, state that even median is insufficient; percentiles (p99, max) are crucial for capturing the full user experience.
A/B Test Results with Skewed Traffic: What's Next?
This tests your ability to spot confounding variables. A good answer invalidates the results due to sampling bias, proposes segmenting the data by device to find the true effect, and suggests re-running the test with correct randomization.

How to query a monthly cohort retention table in SQL?
Tests your ability to translate a core business metric into a multi-step SQL query. A good answer finds each user's acquisition month, joins that back to their activity, and pivots the data into a cohort grid. A red flag is calculating aggregate retention.

Average latency is up 50ms, but p99 is flat. How do you diagnose this?
Tests your grasp of latency metrics. A rising average with flat p99 means the *bulk* of requests (p50-p90) slowed, not the tail. Hypothesize a common bottleneck and segment data by endpoint/user to find it. Red flag: blaming new, slow outliers.
DAU dropped 10%. How do you investigate?
Tests structured problem diagnosis. First, verify the data isn't corrupt. Then, segment the drop by user type (new vs. returning), platform (iOS/Android/Web), and geography to isolate the 'what' before hypothesizing the 'why'.