
What options exist when a story is too large for one sprint?
This tests vertical-slicing discipline versus architectural decomposition. A strong answer covers splitting by user value, checking INVEST criteria, and avoiding task-like layers. A red flag is proposing horizontal database or UI splits that defer feedback.
How should the team handle an oversized user story in Sprint Planning?
WHAT IT TESTS: Protecting the Sprint Goal when a story is too big. ANSWER OUTLINE: Split it vertically with the Product Owner, swarm the top slice, and renegotiate scope rather than overcommitting. RED FLAG: Proposing overtime or horizontal splits.

How do you handle NFRs in the backlog and make them visible?
WHAT IT TESTS: Making NFRs visible and actionable in Scrum. ANSWER OUTLINE: Write NFRs as measurable backlog items with acceptance criteria; embed in Definition of Done; decompose into tasks; automate validation.

How do blockers and impediments differ, and when do you escalate?
It tests whether you separate immediate task stops from chronic drag. Blockers are red-light stops for swarming; impediments are velocity drains surfaced in retrospectives and escalated with data.

How does an engineering manager's role change moving to agile autonomous teams?
Tests understanding of shifting from command-and-control to coaching and enabling teams. Strong answers cite three domains: team coaching, value investment, and environment shaping, plus servant leadership.

What technical and process challenges appear when forming cross-functional product teams?
Tests whether you see cross-functional integration as dissolving handoffs, not renaming teams. Strong answers mention testing in CI/CD, collective estimation, and social friction. Weak answers treat it as a staffing reshuffle that keeps siloed workflows.
How does management evolve in scaled agile versus traditional program management?
This tests whether you see scaled agile shifting management from command to enablement. A strong answer contrasts LeSS manager-as-teacher supporting self-managing teams against traditional program-management command structures.

How would you probabilistically forecast 40 stories using throughput data?
Tests probabilistic forecasting literacy using historical throughput. Good answers gather 8–12 periods of throughput, run Monte Carlo resampling, and present percentile delivery curves (e.g., 50th/85th/95th).

From an engineer's perspective, when does Cycle Time begin and end?
Tests if you set Cycle Time boundaries to expose wait states past coding. Strong answer: starts at In Progress, ends at Done or production, includes review/test, excludes backlog queues, and distinguishes from Lead Time. Red flag: starting at ticket creation.

Explain Little's Law and its practical application in Kanban
This tests your grasp of the WIP-throughput-lead time relationship in stable flow systems. State Lead Time = WIP / Throughput and show lowering WIP cuts lead time if throughput is flat. Beware claiming more WIP raises throughput without increasing lead time.
Explain backlog refinement: purpose, participants, and outcomes
Tests if you treat refinement as team-wide prep, not a solo PO task. Strong answers cite the full team and stakeholders, with outcomes being ready stories and estimates. Red flag: saying only the PO and Scrum Master attend or that it replaces sprint planning.

Two senior developers clash on implementation, derailing sprint planning. Your role?
WHAT IT TESTS: Protecting Scrum events while channeling conflict into productive tension. ANSWER OUTLINE: Park or timebox the debate, reframe positions into shared interests with structured dialogue, and drive to a decision or spike.
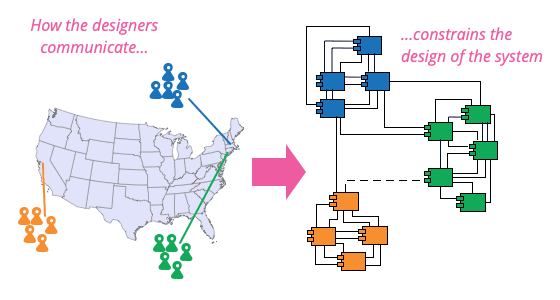
How would you apply Conway's Law to design team structures for microservices?
WHAT IT TESTS: Using org structure as an intentional architecture lever. ANSWER OUTLINE: Map bounded contexts to cross-functional teams; use APIs as contracts; split by decoupling boundary.
Why is velocity as a primary KPI destructive, and what's better?
This tests if you see velocity as a planning gauge, not a performance metric. A strong answer notes points are subjective, cites Goldratt on gaming, and proposes team-driven improvement instead. A red flag is claiming velocity works if averaged over time.

Compare SAFe and LeSS from an engineer's view
Tests whether you see scaling frameworks as workflow design choices. Answers contrast SAFe's PI planning and RTE-managed dependencies with LeSS's single Sprint planning and team-driven resolution. Red flag: calling them interchangeable without citing autonomy.

Decompose a monolith for scaled agile teams
Tests aligning architecture to team boundaries during incremental monolith decomposition. Cover: bounded contexts with isolated data and sagas, backward-compatible versioned APIs, and replacing shared libraries with duplicated code or versioned SDKs.

How would you estimate a cross-cutting initiative in PI Planning?
Tests decomposition of cross-cutting work into team enablers with visible dependencies. Good answer: teams estimate own slices in normalized points, map dependencies on the ART board, and reserve IP buffer.
Design an Upstream Kanban process for product ideas before development
Tests your grasp of pre-commitment demand shaping. A strong answer maps an option-discovery board, defines the commitment point and triage policies, and ties early filtering to reduced downstream variability.

CFD Testing band widens: what does it indicate and what experiments?
This tests flow metric literacy. A widening Testing band means arrivals exceed departures; propose experiments like smaller batches, automation, or dev-test swarming, then measure cycle time. Red flag: blaming testers or demanding headcount without data.

Lead Time vs Cycle Time in Kanban and measuring Cycle Time
Tests whether you distinguish customer wait time from active work. Strong answer: Lead Time is request-to-delivery with queues; Cycle Time is active start-to-finish measured from In Progress to Done. Red flag: treating them as synonyms or ignoring wait states.