How would you design a reproducible ML training pipeline?
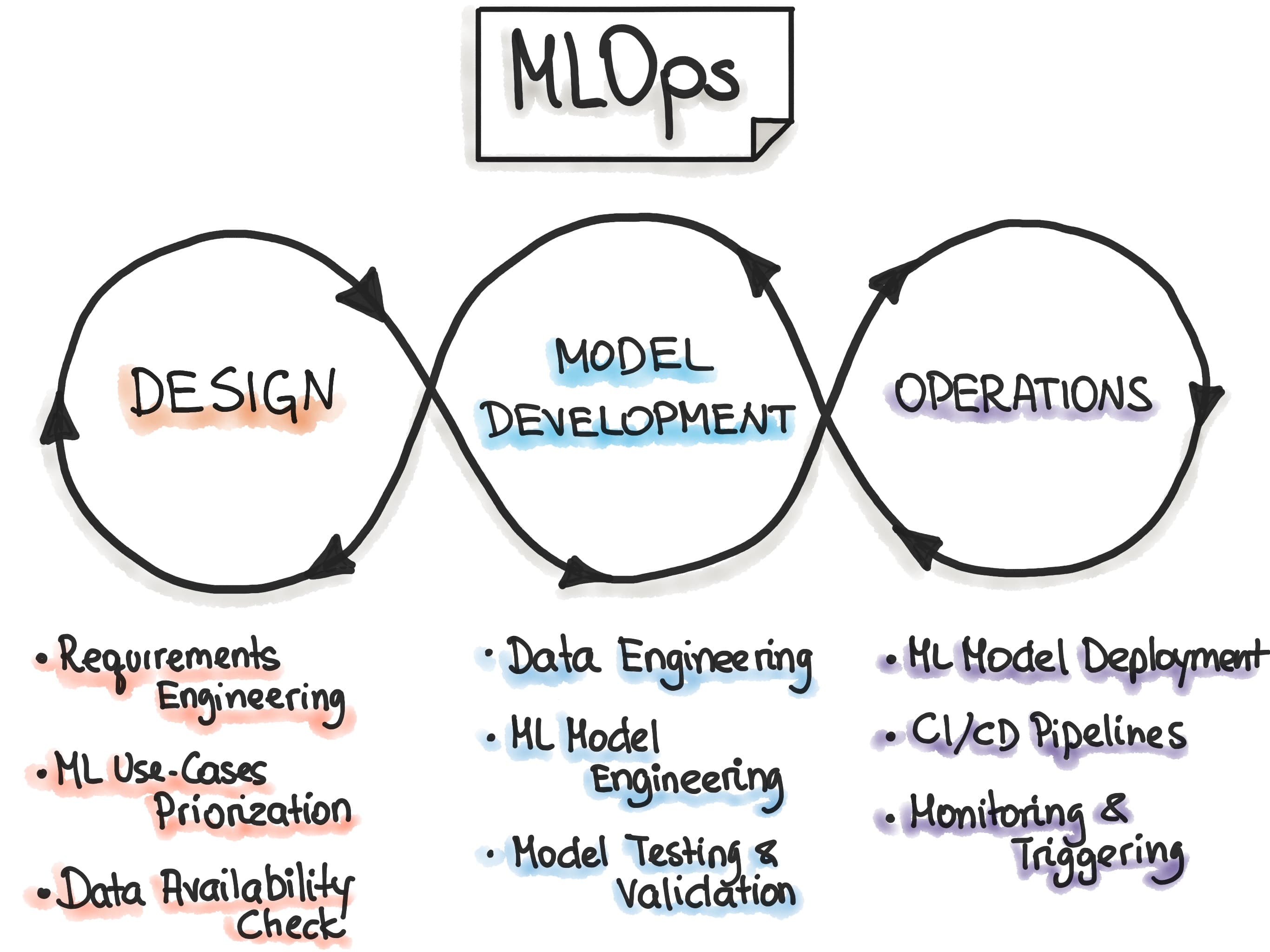
Tests if you can version ML's three moving parts: code, data, and environment. Good answers cover Git for code, DVC or lakehouse versioning for data, and Docker plus locked dependencies for environments.
Tests whether you can engineer reproducibility across ML's three mutable dimensions: code, data, and compute environment. A strong answer sequences Git with commit hashes for code, DVC or lakehouse time-travel for dataset lineage, and Docker images with locked requirements for environments, all orchestrated through a CI/CD pipeline that versions every run artifact and its metadata. Red flag: relying on manual Jupyter notebook execution without pinned dependencies, data snapshots, or automated pipeline triggers.
Read the original → ml-ops.org
- #mlops
- #reproducibility
- #ci-cd
- #versioning
- #machine-learning
Get five bites like this every day.
Tezvyn delivers a daily feed of 60-second tech bites with quizzes to lock in what you learn.