LLM Inference Caching: Pay for Computation Once
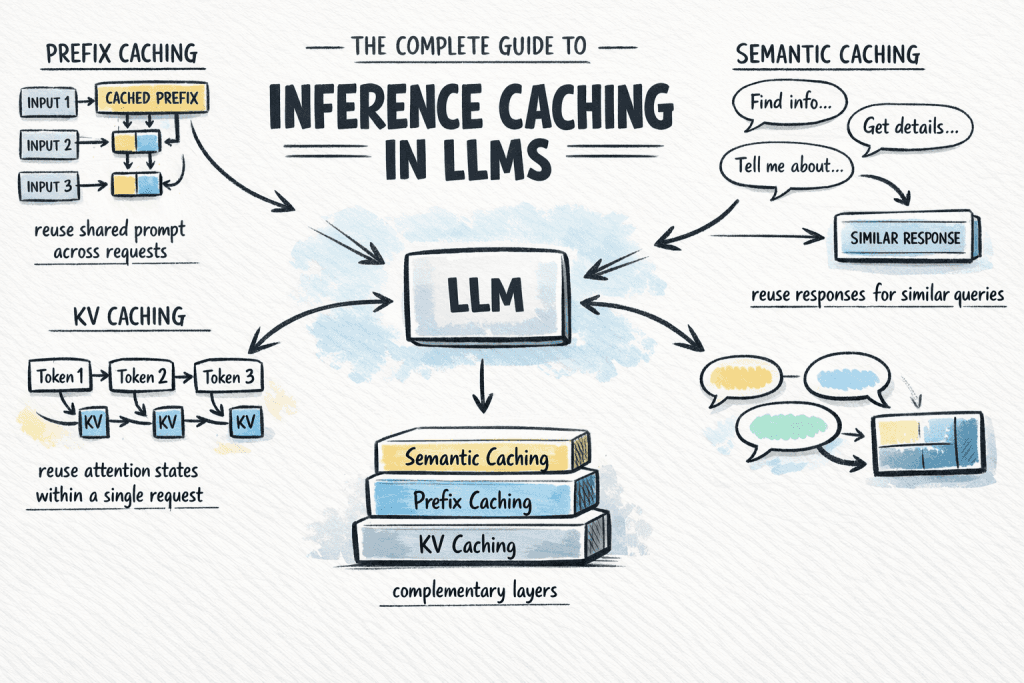
LLM inference caching reuses past computations to cut costs and latency. It avoids reprocessing shared system prompts or serves full answers for common queries without hitting the model. The footgun: semantic caches can return a "similar" but incorrect answer.
LLM inference caching avoids recomputing what a model already processed, saving significant cost and latency. It works at three levels: inside a single request (KV cache), across requests with shared system prompts (prefix cache), or at the application level by matching semantically similar queries (semantic cache). This avoids hitting the model for common questions. The footgun is relying on semantic caching for nuanced queries, where a "similar" cached answer might be subtly incorrect.
Read the original → machinelearningmastery.com
- #llm
- #mlops
- #caching
- #performance
Get five bites like this every day.
Tezvyn delivers a daily feed of 60-second tech bites with quizzes to lock in what you learn.